RSpec-flaky: травим плавающие баги в тестах
Один из основных критериев правильно написанного и работающего теста - его детерминизм. Если код не меняется - результат теста тоже не должен меняться. Однако если вы пишете тесты (иначе зачем вообще читать эту заметку?), то наверняка сталкивались с плавающими тестами. Плавающие тесты - это термиты вашего приложения, они замедляют скорость разработки, скрывают баги и как следствие - стоят денег. Тех самых, на которые печеньки с кофе в офис покупают.
Мы в RNDSOFT тоже иногда сталкиваемся с плавающими тестами. И у нас появился свой маленький, но приятный инструмент, помогающий нам в решении этого вопроса.
Итак, что же такое плавающие тесты? Академическое определение вряд ли будет где-то приведено, поэтому обозначим их, как тесты, которые иногда проходят успешно, а иногда нет. Разработчики по-разному решают эту проблему. Те подходы, с которыми я сталкивался хороши и плохи по-своему.
Настойчивый подход
К примеру, можно перезапускать тесты, пока тест не пройдет. Рабочий подход? Рабочий. Именно так и закрываются проблемы в большинствеCI/CD - если пайплайн не прошел успешно, rspec-retry прогонит его еще пару раз и только после этого отвалится. Или не отвалится, и ветка дальше пойдет в прод. При таком подходе тест сам по себе лишается смысла, поскольку он не гарантирует правильное выполнение покрытого кода.
Безответственный подход
Можно решить проблему по-другому, например, вообще закомментить плавающийexpect и добавить ссылку на него в задачу с пулом таких же закомменченных expect-oв. Тоже вполне рабочая схема. И такая схема используется часто - это логично, ведь менеджеру важнее быстрее протащить фичу в прод, а разработчику не очень хочется глазами полными тоски в исступлении перезапускать тест, в надежде что, что-то изменится.

Подход с выдумкой
Изобретательные господа, например, изGitlab - обвешивают метаинформацию экзампла флагами плавучести (простите) теста и конфигурят среду выполнения либо под пропуск таких тестов, либо под перезапуск.
Правильный подход
Что же делают самые ответственные и дотошные разработчики? Начинают искать причину такого поведения теста. Если не брать во внимание откровенно плохо написанные тесты, например - незафризенное время, реальные обращения к сторонним сервисам или непродуманное кеширование, то в 99.9% случаев причиной будет рандомизированные фабрики. Рандомизированные фабрики - это плохо. Это химера и иллюзия экономии времени. Когда кто-то пишет в теле фабрики словоrandom илиsample - он занимается самообманом. Базовые поля фабрики должны мать максимально предсказуемы и определены. Если фабрика должна возвращать множество различных вариантов экземпляров модели - для этого есть вложенные фабрики, трейты и оверрайд атрибутов создаваемой записи из тест-сьюта. Лучше потратить пару минут и точно знать, какую запись ты тестируешь, чем потом потратить пару часов на поиск модели, атрибута и самое главное - его значения, которое ломает тест.
Но если у вас уже есть такие фабрики и они очень плотно интегрированы в сотни тестов, то ничего не поделаешь - придётся искать.RSpec позволяет указатьseed для генерации одних и тех же псевдослучайных данных при каждом выполнении, а также инструментbisect для сужения диапазона поиска плавающих экзамплов. После этого можно приступать к поиску значений атрибутов модели, которые препятствуют успешному прохождению теста.
Инструмент
В этом вам может помочь гем rspec-flaky. Гем достаточно прост - он сам перезапускает тест(ы) указанное количество раз, выгружает атрибуты указанных моделей в json-ы и, если были и успешно пройденные и проваленные тесты, вычисляет дифф и формирует таблицу, где наглядно видно, какие значения имели атрибуты, когда тест был успешен и не успешен.
Давайте разберём на примере. Есть модельPerson, которая содержит метод#greeting, возвращающий разные приветствия в зависимости от имени.
Модель:
class Person < ApplicationRecord
def greeting
'RARRRGGHH' if name == 'Chewbacca'
end
end
Фабрика:
FactoryGirl.define do
factory :person do
name { ['Chewbacca', 'Han Solo', 'Dart Weider'].sample }
skills do
[
{
strength: 95,
intelligence: 70,
cuteness: 100
},
{
strength: 70,
intelligence: 80,
cuteness: 50
},
{
strength: 100,
intelligence: 90,
cuteness: 15
},
].sample
end
end
end
Тест:
RSpec.describe 'Test example' do
let(:person) { create :person }
it 'should greet you', tables: [Person] do
expect(person.greeting).to match('RARRRGGHH')
end
end
Мы видим, что в среднем тест будет проходить успешно только один раз из трёх - когда фабрика соизволит вернуть значениеChewbacca в атрибут имени. Для того, чтобы определить, какие атрибуты модели меняются от запуска к запуску воспользуемся нашей утилитой:
$ rspec-flaky spec/example_suite/person_spec.rb -i 5
Флаг -i определяет количество итераций. Гем создаст result.html в tmp/flaky_tests в папке проекта. Если за указанное число итераций встретятся, как проваленные, так и успешные тесты, то сформируется таблица со списками атрибутов:
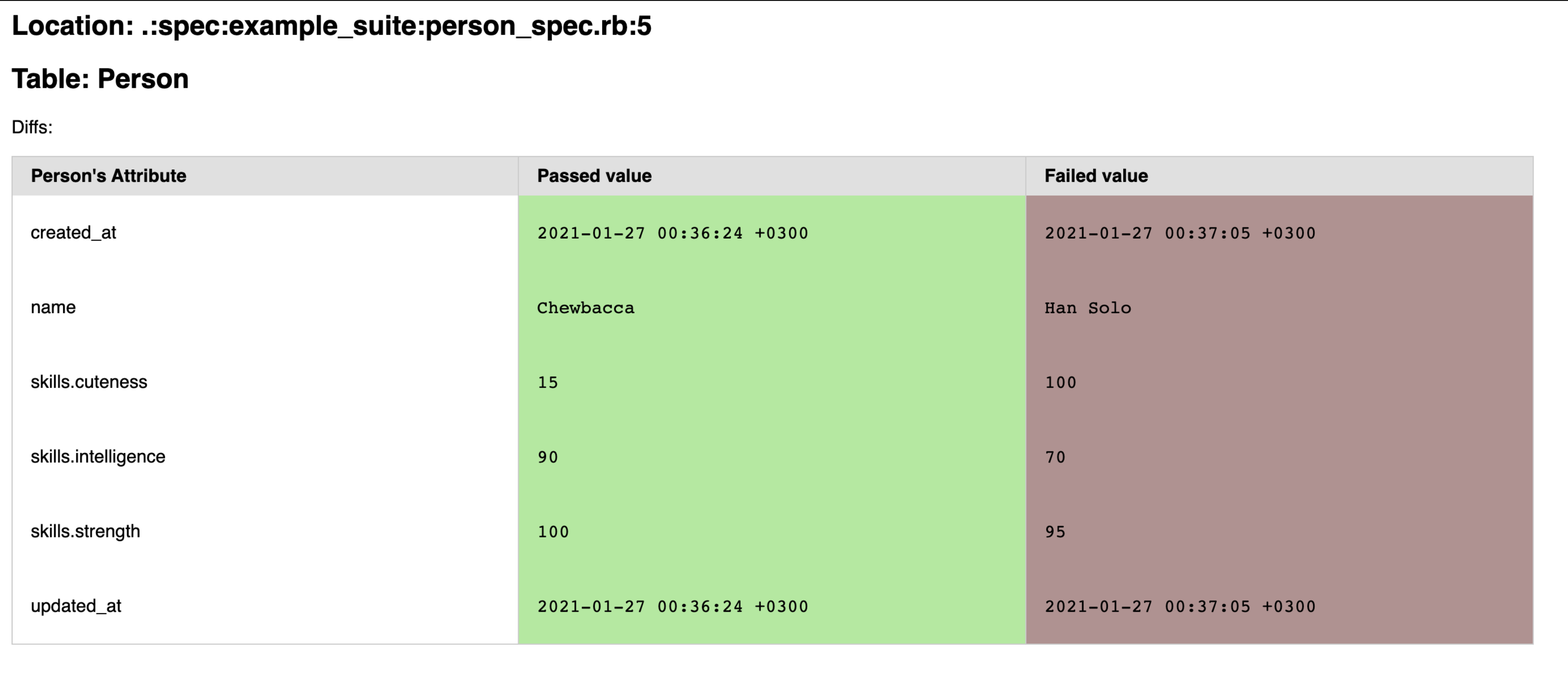
Верхняя строчка содержит - относительный путь к тесту. Предполагается, что поиск атрибутов будет производиться точечно, но можно запустить весь тест-сьют или папку целиком - тогда каждая таблица сравнений будет сопровождаться информацией о соответствующем таблице экзампле.
Вы можете указать несколько таблиц в качестве подозреваемых. Какая именно модель перед вами подскажет строкаTable.
Ну и самое важное - таблица диффов. Левый столбец содержит список атрибутов подозреваемой модели. Обратите внимание - атрибуты вложенных объектов разделены точкой. Средний и правый столбцы показывают значения атрибутов в момент последнего успешного и проваленного тестов соответственно. Да, дизайн мог бы быть и покрасивее, но:

В целом, такого результата достаточно для существенного сокращения времени для поиска. Однако причина может скрывать в какой-нибудь модели, где вы ожидали подвоха меньше всего. Для поиска таких мест можно дампнуть всю базу данных целиком:
rspec-flaky spec/example_suite/person_spec.rb -i 5 -d
В результате, мы получим папку с дампнутыми БД на каждый экзампл с одноименным названием, расположенную в tmp/flaky_tests.
Стандартные опции исполнения rpsec передаются через два дефиса:
rspec-flaky spec/example_suite/person_spec.rb -i 5 -d -- -fdoc
Перспективы:
- Пока дамп БД поддерживается только
Postgres. По мере необходимости планируется добавить поддержкуMySQLиSQLite3. - Выгрузка базы данных осуществляется системным вызовом - это отдельная транзакция, поэтому для этого приходится устанавливать
truncationстратегию дляDatabaseCleaner. Этого хотелось бы избежать путём выгрузки всех моделей в CSV-файлы и добавлением команды, выполняющей их запись в таблицу для дальнейшего исследования.
Ну пока!