Что делать, когда кругом враги?

Когда вы интегрируете между собой две системы, одной из первоочередных задач для вас станет сопоставление существующих данных. Самый простой пример - это пользователи. В ИС1 много лет работали люди, и в ИС2 тоже, причем, пока не было задачи интеграции, никто не озаботился тем, чтобы вести единую идентификацию.
В довесок она может быть (и скорее всего будет) построена на кардинально разных принципах! Для ИС1 программист завел в базе bigint primary-key с автоинкрементом и автоматически получал новый номер для каждого пользователя. При разработке ИС2 психическое здоровье разработчика или аналитика (а возможно и обоих) могло быть не столь крепким, и было принято решение использовать в качестве однозначного идентификатора ФИО + дату рождения.
И когда нужно передать, скажем, заявку из ИС1 в ИС2, то хотелось бы не передавать внутри неё все, что мы знаем о пользователе, который её оставил. Ну и ещё больше не хочется потом с использованием всего этого вороха данных искать соответствующую запись у себя, встраивая огромную логику сопоставления в процесс обработки заявки. Хочется получать некий заранее заданный идентификатор, по которому можно легко и быстро достать корректного пользователя из своей базы.
Для этого будет хорошо предварительно сопоставить базы двух ИС, найти совпадения, и либо ИС2 согласится сохранять в пару к своему идентификатору идентификатор из ИС1, либо победит зло и bigint дополнится “ФИО + дата рождения” в базе ИС1.
Мы не будем говорить о том, как правильно сопоставлять людей - по ИНН, СНИЛС, паспорту или всему сразу. Мы рассмотрим довольно неожиданную проблему - а что если ИС1 и ИС2 не доверяют друг другу и не готовы показать свой список пользователей другой системе?!

При независимом партнерстве ситуация в целом не редкая. Есть например некая платформа, агрегирующая в себе разные данные людей из различных источников, и есть компания, которая может предоставить эти данные. Но компания не хочет раскрывать платформе полный список своих клиентов (предоставляя таким образом халявные лиды), а готова отдавать данные только по тем людям, которые уже работают с платформой. Платформа в свою очередь также не желает "сливать" свою базу по сходным причинам. Но работать надо!
В этом случае на помощь могут прийти алгоритмы хэширования (хэш-функции). Кроме того, что результат хэш-функции напрямую зависит от входных данных (то есть два одинаковых набора данных всегда дадут один и тот же результат), по этому результату невозможно восстановить исходные данные. Фарш невозможно провернуть назад… Ладно, вру, возможно с помощью радужных таблиц, по сути перебором, но об этом позже. Есть ещё коллизии, но там тервер говорит "да ладно, не кипишуй…".
Итак, к сути - легким движением руки ФИО из базы ИС1 превращаются в веселую мешанину символов, передаются в ИС2, где сравниваются с подобной мешаниной, сформированной для каждой записи в базе ИС2. И вуаля! ИС2 может записать к себе в базу для Иванова идентификатор этого Иванова из ИС1 - 45. И во всех дальнейших взаимодействиях, где будет иметься в виду Иванов, обе системы спокойно могут использовать 45.
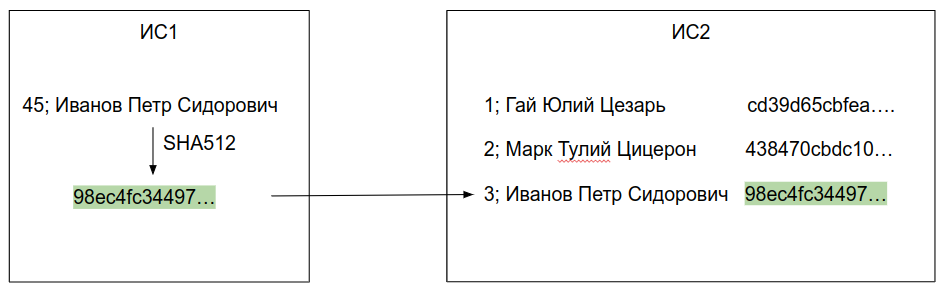
Естественно, чтобы не очень сильно насиловать CPU, обе ИС должны провести процедуру вычисления хэшей заранее и хранить результаты в базе, чтобы по мере необходимости в синхронизации идентификаторов они были всегда под рукой. Кстати, при желании такой результат и как общий идентификатор можно использовать, если это укладывается в ваше представление о том, как должен выглядеть primary-key записи в базе.
Выбор полей для сопоставления остается на совести разработчиков. ФИО, ИНН, СНИЛС, номер паспорта, дата рождения, девичья фамилия матери, название куска камня, что был в зените в момент рождения. Можно использовать несколько разных наборов, если есть разные кейсы заполненности профилей. В общем все что угодно при одном очень важном НО - то, что вы будете отдавать хэш-функции на вход должно быть хоть сколько-нибудь длинным!

Пример: если строкой для хэширования будет серия и номер паспорта, то это суммарно 10 символов(экзотику в расчет не берем), то есть всего лишь 10 миллиардов вариантов различных значений. Далеко не самая современная видеокарта ATI Radeon HD 4850 X2 позволяет генерировать до 2,2 миллиардов хешей по алгоритму MD5 в секунду. То есть меньше, чем через 5 секунд все возможные значения для всех возможных паспортов будут готовы, останется только сравнить и получить на выходе исходный номер. Радужные таблицы VS безопасность - 1:0.
Но уже добавив к серии и номеру паспорта телефон в международном формате мы получаем примерно 15 тысяч лет, что делает нас достаточно защищенными от школьника за старым папкиным компом. Победа!
Дальше можно накрутить несколько последовательных применений хэш-функций, соль, перец, оливочку… И в целом добиться приемлемой защиты от эникейщиков компании, с которой вы проводите подобную интеграцию. Особенно, если ИТ для них не профильная сфера.
Да, внедряя, например, "перчение" вы можете потерять в оптимальности из-за невозможности нормально предпросчитывать и хранить в базе хэши. Поэтому, как и в любом вопросе, связанном с безопасностью, надо вовремя остановиться, пока безопасность не перешла в паранойю. В конце концов, скорее всего, в вашем API найдется десяток других более простых способов спереть весь набор данных, кроме многоуровневого хэширования и вопрос серьезного промышленного шпионажа вы будете закрывать другими методами, оставив хэширование как "защиту от дурака".

- Хэшируйте как можно более длинные объемы данных;
- Используйте более менее современные алгоритмы, с минимальной вероятностью коллизии и медленным хэшированием.
OWASPрекомендуетArgon2илиbcryptс предварительным хэшированиемSHA. Но в вашем случае может быть достаточно парыSHA512каскадом; - Следует из предыдущего пункта - подбирайте решение под задачу, чтобы overengineering не стал бесполезным over-геморроингом.