Rapidity: распределённый rate limiting
Когда ваш продукт начинает активно использоваться, то перед вами обязательно встаёт вопрос масштабирования, а вслед за ним и проблема ограничения доступа к чему-нибудь: Rate Limiting.
RNDSOFT не исключение, поэтому в этой статье мы расскажем небольшую историю и поделимся своим инструментом (💎Ruby-гем в студию!), который уже давно используем на проде.

Обычно с понятием Rate Limiting сталкиваются в контексте ограничения числа HTTP-запросов к вашим собственным ресурсам, либо к чужим, но также в контексте HTTP-взаимодействия. Для решения таких проблем существует множество вариантов и инструментов, это и limit_req для nginx, и Ratelimit для traefik, но не всегда они подходят. Например, если для обеспечения отказоустойчивости вам надо ходить через несколько nginx, то как синхронизировать счётчики между ними?
В нашем случае ситуация иная: нам надо ограничивать число исходящих от нас "запросов", которые по своей сути не совсем HTTP. Ну формально они, конечно, HTTP, однако логическая сущность "запрос" состоит из несколько запросов по разным адресам и с разными параметрами, а ограничения налагаются на высокоуровневое понятие "запрос" целиком. Получается классический Distributed Rate Limiting как он есть.
Distributed Rate Limiting
Проблема в общем случае не тривиальная, но в интернете существует огромное (бесконечное?) количество материалов на это тему. Тут вам и Fixed Window против Sliding Window, и Leaky/Token Bucket, и многое другое. В нашем случае речь пойдёт про конкретный гем, реализующий один из самых простых и надежных вариантов, и которым мы хотим поделиться с другими.
Задача
Есть СМЭВ-сервис (поставщиком является 🚨 МВД), который вводит для клиентов ограничения на число отправляемых запросов. Вот так они выглядят в бою:
limits = [
{ interval: 60, threshold: 300 }, # в минуту - 300
{ interval: 3600, threshold: 15_750 }, # в час - 15 750
{ interval: 86_400, threshold: 300_000 }, # в сутки - 300 000
{ interval: 604_800, threshold: 1_500_000 }, # в неделю - 1 500 000
{ interval: 2_592_000, threshold: 6_000_000 }, # в месяц - 6 000 000
]На горяченькую - прямо из кода ;)
Одно из направлений, в которых RNDSOFT имеет огромную экспертизу - это работа со СМЭВ. Мы много и плотно работаем как с коммерческими, так и с государственными клиентами - отсюда и пример.
Поскольку система не только высоконагруженная, но вдобавок еще и отказоустойчивая с определённым уровнем избыточности, то как только появились ограничения - сразу появилась проблема распределённого учёта запросов.
Решение
В мире Ruby есть несколько решений/библиотек по данной проблеме, но как всегда, в каждом есть нюансы: либо решение слишком сложное, либо у него отсутствуют надёжные интеграционные тесты, а проверить "на глаз" - так себе идея. В результате мы сделали своё на Redis с максимальным упором на простоту и понятность - чтоб и "на глаз" можно было проверить, и настоящими тестами обложили и протестировали. Встречаем: rapidity!
- с помощью SET и параметров EX/NX создаём ключ с квотой;
- с помощью DECRBY уменьшаем квоту, пока не дойдём до 0;
- если квоту исчерпали - ничего не делаем, а ждём удаления ключа по TTL.
Для реализации атомарности используем возможность исполнения LUA-скрипта.
-- args: key, treshold, interval, count
-- returns: obtained count.
-- this is required to be able to use TIME and writes; basically it lifts the script into IO
redis.replicate_commands()
-- make some nicer looking variable names:
local retval = nil
-- Redis documentation recommends passing the keys separately so that Redis
-- can - in the future - verify that they live on the same shard of a cluster, and
-- raise an error if they are not. As far as can be understood this functionality is not
-- yet present, but if we can make a little effort to make ourselves more future proof
-- we should.
local key = KEYS[1]
local treshold = tonumber(ARGV[1])
local interval = tonumber(ARGV[2])
local count = tonumber(ARGV[3])
local current = 0
local to_return = 0
local redis_time = redis.call("TIME") -- Array of [seconds, microseconds]
redis.call("SET", key, treshold, "EX", interval, "NX")
current = redis.call("DECRBY", key, count)
-- If we became below zero we must return some value back
if current < 0 then
to_return = math.min(count, math.abs(current))
-- set 0 to current counter value
redis.call("SET", key, 0, 'KEEPTTL')
-- return obtained part of requested count
retval = count - to_return
else
-- return full of requested count
retval = count
end
return {retval, redis_time}Как видите, сам код с логикой и ветвлением занимает всего несколько строк.
Пример
В примере мы используем не единичный счётчик, а более сложный вариант - несколько счётчиков объединены в один, а при обращении происходит работа с каждым счетчиком по очереди:
# Rapidity::Composer#obtain
def obtain(count = 5)
@limiters.each do |limiter|
count = limiter.obtain(count)
break if count == 0
end
count
end limits = [
{ interval: 60, threshold: 300 }, # в минуту - 300
{ interval: 3600, threshold: 15_750 }, # в час - 15 750
{ interval: 86_400, threshold: 300_000 }, # в сутки - 300 000
{ interval: 604_800, threshold: 1_500_000 }, # в неделю - 1 500 000
{ interval: 2_592_000, threshold: 6_000_000 }, # в месяц - 6 000 000
]
@limiter = Rapidity::Composer.new($redis, name: $app, limits: limits)blocked = false
obtainer.each_obtained(BULK_SIZE) do |request|
if blocked
release(request)
next
end
if @limiter.obtain(1) <= 0
blocked ||= true
release(request)
next
end
process(request)
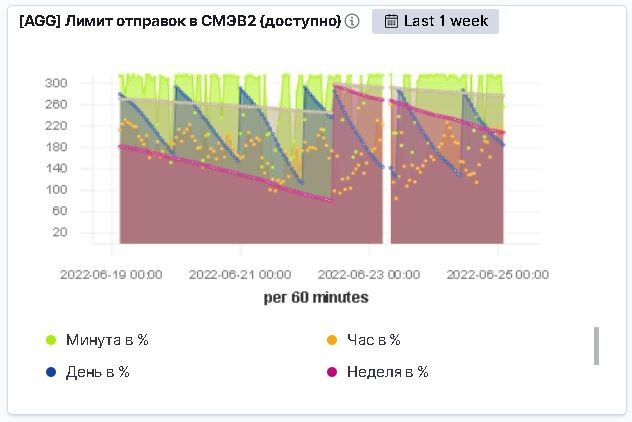
endНапоследок картинка из мониторинга, где можно увидеть как в динамике работают лимиты:
Как обычно для заинтересовавшихся хорошие статьи по теме:
- Сети для самых маленьких: Алгоритм Leaky bucket - просто и с картинкой
- На вики TLDR - более-менее всё описано
- При написании статьи я смотрел на гем prorate, однако мы ❗ никогда ❗ его не использовали.