Распределенный отказоустойчивый мониторинг через бастион хост
Бесконечно можно смотреть на 3 вещи: как работает разработчик, как бежит пайплайн в gitlab и как появляются данные на графиках в grafana.
У нас было 2 мониторинга, 75 node-exporter и множество других экспортеров от комьюнити, не то, чтобы это все было нужно в проде, но раз начал коллекционировать метрики, то иди в своем увлечении до конца.

Вступление
Когда-то деревья были большими, жизнь простой, трава была гораздо зеленее, а мир готов был принять тебя и твой открытый ум. Первоначально у нас был конечно же Prometheus, но потом мы поддались модным трендам и веяниям и решили перейти на VictoriaMetrics. Переход прошел почти идеально гладко. Перешли мы на простую связку:
- 1 инстанс victoriametrics (без всяких select и insert)
- 1 инстанс vmagent
- 1 инстанс vmalert
И все работало хорошо, пока была связность между ДЦ мониторинга и локальными (для облака) машинами. Но в рамках оптимизационных работ по информационной безопасности мы перешли на работу через бастион хосты, после этого стало проблематично собирать метрики с машин в удаленном от системы мониторинга облаке. В данной статье мы расскажем, к какому решению мы пришли. Схема ниже иллюстрирует как было до:
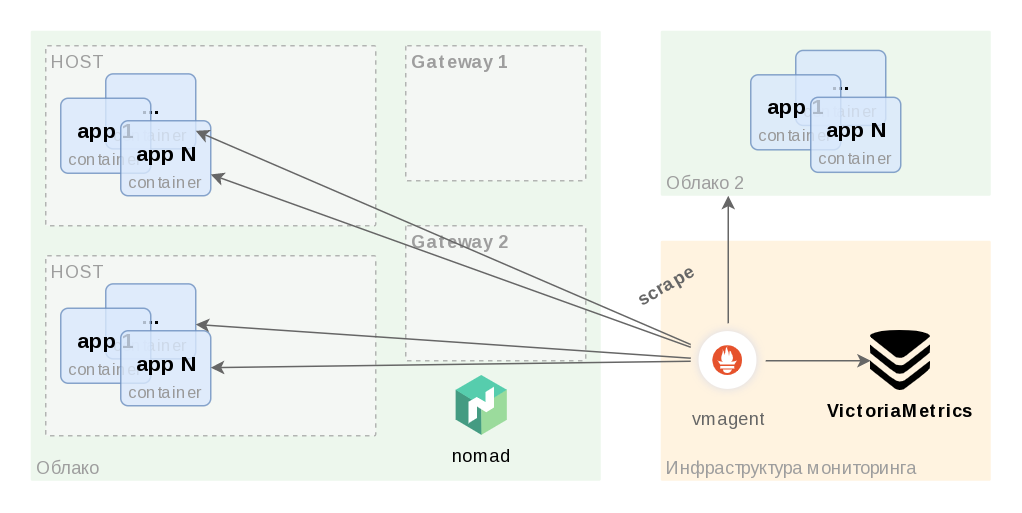
Т.к. vmagent, который находится в инфраструктуре мониторинга, не может собирать метрики, значит нам нужен другой vmagent (подсказывает нам капитан), который из облака будет собирать метрики и доставлять и бережно складывать в victoriametrics. Но тут возникает проблема того, что тогда придется единственный конфиг разрезать на 2 разных конфига и как-то их деплоить.
Дополнительно к этому всему мы в облаке все сервисы запускаем в более чем одном экземпляре для отказоустойчивости, и к vmagent очень хотелось бы применить тот же подход - запускать в нескольких экземплярах в нескольких зонах. Кроме того, если деплоить оба vmagent с одинаковыми конфигами, нужно как-то решать проблему дедупликации метрик.
Итого суммируем проблемы, которые нам надо решить:
- Разделение конфигов и их деплой.
- Отказоустойчивость vmagent, который будет собирать метрики в облаке (3 инстанса).
- Из-за п.2 vmagent нужно запускать в разных ДЦ.
- Из-за п.2 требуется дедупликация метрик.
Конфиг
Итого мы решили, что у нас будет 3 инстанса vmagent: 2 инстанса с единой конфигурацией, которые будут собирать метрики в закрытой инфраструктуре облака, а еще один инстанс vmagent будет как и раньше заниматься сбором метрик с остальной инфраструктуры. Это была самая простая часть, конфиг prometheus.yml для vmagent в облаке:
Если внимательно присмотреться, то можно увидеть, что некоторые параметры в конфиге шаблонизируются jinja2, поскольку мы катаем всё с помощью ansible.
Дедупликация
Итак, конфиг для vmagent у нас готов, как из него видно, targets, которые мониторятся, будут браться из Consul Service Discovery, и поэтому оба vmagent у нас будут собирать одинаковые метрики - будут подключаться к одному кластеру Consul. Но когда 2 vmagent заработают, метрики из них будут дублироваться и графики в grafana "поедут". Это может сильно потрепать нервы команде поддержки и сопровождения...
Чтобы решить эту проблему, нам нужно перед запуском vmagent включить поддержку дедупликации в самой VictoriaMetrics(а вы говорите хайп и не надо было переезжать на VictoriaMetrics). Добавляем в команду запуска victoriametrics параметр --dedup.minScrapeInterval=30s и радуемся.
Фрагмент из Dockerfile команды запуска victoriametrics:
ENTRYPOINT [ "/usr/local/bin/victoria-metrics-prod" ] CMD ["--storageDataPath=/storage", \ "--graphiteListenAddr=:2003", \ "--opentsdbListenAddr=:4242", \ "--httpListenAddr=:8428", \ "--influxListenAddr=:8089", \ "--vmalert.proxyURL=http://vmalert:8880", \ "--retentionPeriod=24", \ "--dedup.minScrapeInterval=30s"]
Как заявляет производитель, --dedup.minScrapeInterval нужно устанавливать равным scrape_interval из prometheus.yml. После включения дедупликации в VictoriaMetrics внимательно проверьте конфигурационные файлы всех vmagent. Ну и конечно же нужно не забыть убрать аналогичную job_name из конфига vmagent, который по-прежнему будет крутиться в инфраструктуре мониторинга, рядом с теплой "Викой".
Отказоустойчивость кластера
Переходим к конфигурации и деплою vmagent в облаке. Запускать vmagent будем как раз на наших бастион хостах - их у нас 2, они в разных ДЦ, и использовать для этого будем Nomad от HashiCorp. Но нам мало запустить агентов на разных машинах в разных ДЦ, мы хотим именно кластерный режим работы - и он есть! Отличается он несколькими параметрами:
/usr/local/bin/vmagent-prod --promscrape.config=/local/configs/prometheus.yml --remoteWrite.url=http://IP_VICTORIAMETRICS:8428/api/v1/write --remoteWrite.tmpDataPath=/vmagentdata --promscrape.cluster.replicationFactor=2 --promscrape.cluster.membersCount=2 --promscrape.cluster.memberNum=0
Аналогичным образом будет конфигурироваться второй vmagent, только параметр --promscrape.cluster.memberNum нужно будет для второго установить в "1" - у каждого свой уникальный номер в кластере.
--promscrape.cluster.membersCount - устанавливает, сколько будет vmagent в кластере
--promscrape.cluster.memberNum - уникальный номер vmagent в кластере
--promscrape.cluster.replicationFactor - по умолчанию только один агент из кластера собирает метрики, этот параметр позволяет добавить отказоустойчивость в наш кластер и после установки этого параметра в "2", оба vmagent будут заниматься сбором метрик.
В качестве оркестратора мы используем давно полюбившийся нам nomad:
Ну и сборка образа самого vmagent из Dockerfile:
И важная мелочь в скрипте start_vmagent.sh
#!/bin/bash
set -ex
echo $NOMAD_DC
echo $NOMAD_ALLOC_INDEX
/usr/local/bin/vmagent-prod \
--promscrape.config=/local/configs/prometheus.yml \
--remoteWrite.url=http://${VMAGENT_VICTORIAMETRICS_SERVER}:8428/api/v1/write \
--remoteWrite.tmpDataPath=/vmagentdata \
--promscrape.cluster.replicationFactor=2 \
--promscrape.cluster.membersCount=2 \
--promscrape.cluster.memberNum=${NOMAD_ALLOC_INDEX}В каждом запущенном контейнере есть переменные окружения Nomad, вот эти https://developer.hashicorp.com/nomad/docs/runtime/interpolationmembersCount#job-related-variables, при запуске vmagent в нужном ДЦ, мы будем использовать переменную NOMAD_ALLOC_INDEX, которая в стартовом скрипте в момент запуска джобы пронумерует наши агенты "правильным" образом.
Итоги
В результате мы получили отказоустойчивый, распределенный кластер vmagent, разделили конфиг prometheus.yml, сделали дедупликацию метрик в victoriametrics. Всё работает надёжно и безопасно. Итог того, что у нас получилось, на схеме ниже.
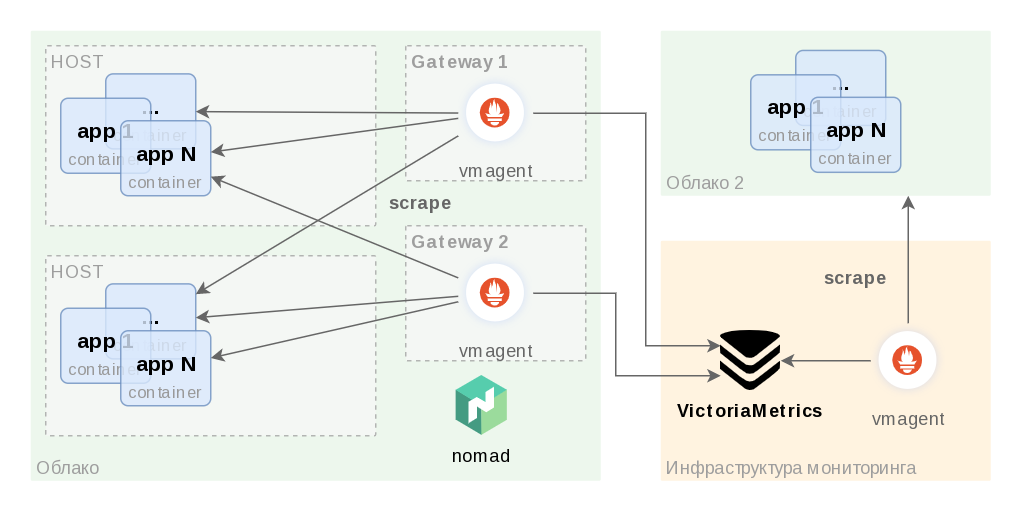
Библиотека:
- Раз, два три - про SSH бастион/Jump хосты
- VictoriaMetrics cluster version - про кластера Виктории
- VictoriaMetrics HA - про HA и дедупликацию
- VM Service Discovery - список SD включая consul, nomad и пр.