ETL в мультитенантной архитектуре

Если данные существуют — значит они нужны бизнесу
В данной статье хотим поделиться рецептом: как сделать сбор, обработку и загрузку продуктовых данных в хранилище на Ruby On Rails для последующего анализа.
Предположим, что у вас есть мультитенантное SaaS приложение, если простыми словами, то это web приложение, где есть возможность обслуживать пользователей из разных организаций независимо друг от друга в рамках одного сервиса, т.е. изолировать подписчиков, чтобы данные одного подписчика были недоступны другому.
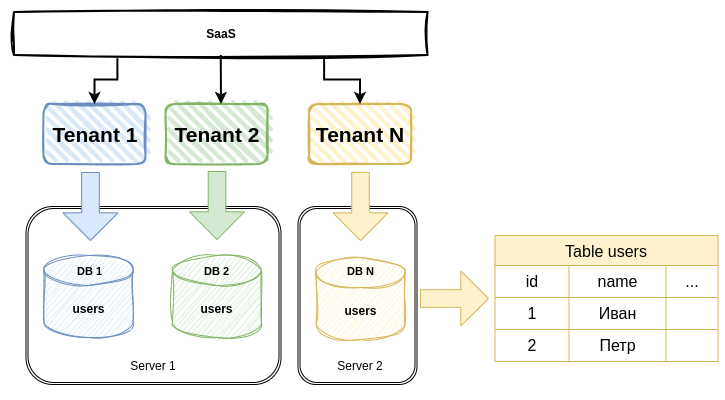
Из-за этой специфики мультитенантной архитектуры, когда данные каждого тенанта (подписчика) изолированы на одном из уровней архитектуры приложения, у вас нет легкой возможности получить объединенную статистику по всем тенантам, например, количество пользователей в вашем сервисе. Вам придется запрашивать эту статистику в каждом тенанте, а потом агрегировать результаты.
Сам процесс сбора, предварительной агрегации, предобработки и загрузки в хранилище называется ETL (Extract, Transform, Load), не путайте с ELT, когда данные обрабатываются после их загрузки в хранилище.
Итак, для начала сделаем отдельное пространство имен в приложении, в дальнейшем вы можете вынести его в отдельный gem и engine или даже микросервис
# app/model/etl.rb module Etl end
Для организации хранилища данных будем использовать отдельную базу (например PostgreSQL), которую в дальнейшем будем подключать к инструментам анализа.
Почему не использовать уже имеющиеся базы данных и просто подключить их? В текущей базе наверняка содержатся чувствительные данные, например, персональные данные, при этом для анализа они не нужны, т.к. там вы оперируете статистикой и количественными характеристиками. Кроме этого, текущие базы могут находиться в закрытом контуре, и не всегда возможно организовать прямое подключение внешних потребителей, таких как инструменты BI.
Схема развертывания будет выглядеть примерно так:
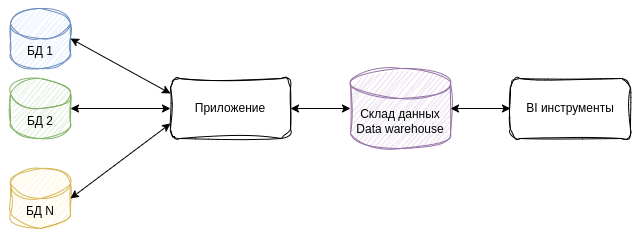
Воспользуемся возможностью Ruby on Rails подключаться к нескольким базам данных с Active Record и подключим новую базу к нашему приложению.
Для этого добавим в config/database.yml
development:
warehouse:
adapter: postgresql
database: warehouse_development
migrations_paths: db/warehouse_migrate
...
test:
warehouse:
adapter: postgresql
database: warehouse_test
migrations_paths: db/warehouse_migrate
...
production:
warehouse:
adapter: postgresql
database: warehouse_production
migrations_paths: db/warehouse_migrate
...Теперь наполним наш склад простыми данными (типа пользователи) и бизнес сущностями, которые генерируют пользователи, т.е. теми данными, которые хранятся в обычных таблицах и которые понадобятся для количественного анализа.
Для этого создадим отдельные модели данных, которые будем использовать для извлечения и преобразования записей, а в дальнейшем организуем сохранение в хранилище.
Создадим концерн, в котором включим режим только чтение и отключим STI, чтобы Rails не пыталась заменить класс модели
# app/models/etl/model.rb
module Etl::Model
extend ActiveSupport::Concern
included do
# Отключаем STI, т.к. колонки _type_disabled в таблице не существует,
# то механизм STI не сработает
self.inheritance_column = :_type_disabled
end
# Отключим запись, для предотвращения случайной перезаписи
def readonly?
true
end
endИ пример самой модели для чтения данных через прямое наследование
# app/models/etl/user.rb class Etl::User < User include Etl::Model end
В данном случае сохраняется возможность пользоваться связями и методами реальной модели, например etl_user.messages.count
Или мы можем сделать модель без внутренней логики и связей, для этого используем явное указание table_name
# app/models/etl/user.rb class Etl::User include Etl::Model self.table_name = 'users' end
В данной модели мы можем делать явное преобразование полей и агрегацию связанных данных
# app/models/etl/user.rb
class Etl::User < User
include Etl::Model
# Пример агрегации данных
def messages_count
self.messages.count
end
# Пример предобработки полей
def locked
locked_at.nil?
end
endТеперь после того, как мы умеем читать и преобразовывать данные для последующего анализа, нам нужно загрузить их в хранилище. Для этого в хранилище должно быть специальное место под эти данные.
Создадим миграцию, в которой создадим таблицу для хранения пользователей, но без лишней чувствительной информации
> rails g migration CreateUser id:bigint messages_count:bigint locked:boolean --database warehouse create db/warehouse_migrate/20230714070604_create_user.rb
# db/warehouse_migrate/20230714070604_create_user.rb
class CreateUser < ActiveRecord::Migration[7.0]
def change
create_table :users do |t|
t.bigint :id
t.bigint :messages_count
t.boolean :locked
t.timestamps
end
end
endУ нас мультитенантная архитектура, поэтому при загрузке данных из разных тенантов id пользователя может повторяться, поэтому немного модифицируем миграцию и добавим уникальное название тенанта, и можно добавить название окружения, в котором запущено приложение (если у вас их несколько). После изменений миграция будет выглядеть так:
# db/warehouse_migrate/20230714070604_create_user.rb
class CreateUser < ActiveRecord::Migration[7.0]
def change
create_table :users do |t|
t.string :instance
t.string :tenant
t.bigint :tenant_id
t.bigint :messages_count
t.boolean :locked
t.timestamps
end
end
endСоответственно, добавим в модель преобразование поля id в tenant_id и дополнительные поля instance и tenant, т.к. данное действие потребуется всем моделям, просто добавим их сразу в наш концерн
# app/models/etl/model.rb
module Etl::Model
...
def tenant_id
id
end
def tenant
# Индентификатор тенанта, например из переменной окружения
ENV.fetch('APP_TENANT', 'unkonwn')
end
def instance
# Индентификатор окружения, например из переменной окружения
ENV.fetch('APP_INSTANCE', 'unkonwn')
end
endТеперь создадим модель для записи на склад данных, для этого сначала сделаем базовый класс для моделей склада
# app/models/etl/warehouse/base.rb class Etl::Warehouse::Base < ActiveRecord::Base self.abstract_class = true self.inheritance_column = :_type_disabled establish_connection :warehouse end
И модель наших пользователей на складе данных
# app/models/etl/warehouse/user.rb class Etl::Warehouse::User < Etl::Warehouse::Base end
Теперь осталось прочитать и сохранить. Можно реализовать колбэк after_save и сохранять данные сразу и на склад или делать полную синхронизацию, например раз в сутки, и заполнять наш склад
class Etl::LoadTables
def execute
Etl::User.find_each do |user|
# Найдем или создадим новую запись на складе
warehouse_user = Etl::Warehouse::User.find_or_initialize_by(instance: instance, tenant: tenant, tenant_id: user.id)
# Получим список полей для сохранения из модели склада, в данном случае они будут такие:
# id, instance, tenant, tenant_id, messages_count, locked, created_at, updated_at
attribuses = warehouse_user.attribute_names - %w[id tenant_id instance tenant]
# Сохраним уже предобработанные поле из Etl::User в Etl::Warehouse::User
warehouse_user.assign_attributes(user.slice(attrs))
warehouse_user.save!
end
end
endДанный класс я упростил, чтобы показать механику сохранения. В боевом виде этот класс можно масштабировать для обработки всех моделей на складе и позаботиться об обработке случая удаления данных на складе в случае удаления их в приложении. Это может быть прямое удаление или добавление специальной пометки.
Вывод
Мы получили процесс ETL для простых данных в мультитенаной архитектуре, мы очистили данные от лишней информации, агрегировали связанные данные в количественные характеристики и наладили ежедневный сбор. Подключив, например, yandex datalens к базе, вы уже можете строить и визуализировать данные.