В поисках утраченного индекса

Всем привет! Сегодня я расскажу небольшую историю о том, как бездумное удаление одного индекса в БД пощекотало нам нервы.
Небольшая вводная
Web приложение на ruby on rails. Одним из главных элементов приложения является гем doorkeeper.
Doorkeeper это самый популярный гем для добавления поддержки oauth2 протокола со стороны сервера (провайдера данных). Гем живой, постоянно обновляется и соблюдает требования протокола.
Цель приложения - быть адаптером к государственным сервисам.
Эти сервисы требуют использования ГОСТ Р 34.10-2012 алгоритма шифрования, довольно часто имеют специфические АПИ, протоколы и монументальную документацию, в которой тяжело разобраться.
А нашим клиентам хочется простого, понятного и самое главное безопасного взаимодействия. Собственно oauth2 относится к таким протоколам.
Клиент -> Наш адаптер-> Гос сервис
С вводной закончили. Теперь к проблеме
Разработали мы это приложение и запустили его в прод. Все хорошо, клиентская база растет, нагрузка постепенно тоже. Спокойно себе живем и пилим новые фичи.
Но однажды спокойную разработку прерывает сообщение девопса:
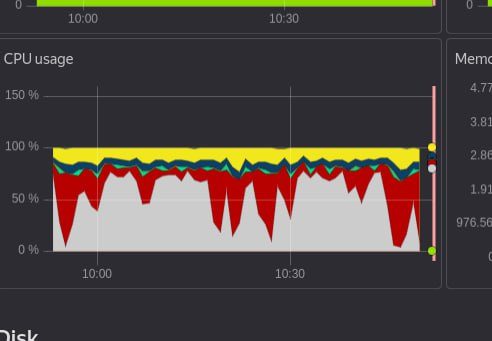
Исследование проблемы
Красное на графике это iowait, значит скорей всего в приложении есть неоптимизированные запросы.
Выгрузили из БД ЯО список самых тяжелых запросов и в топе был такой:
SELECT 1 AS one FROM "oauth_access_tokens" WHERE "oauth_access_tokens"."token" = 'eyJraWQiOiJvSGxKcW…cg'
Очень удивились такому “чемпиону”. Таблица oauth_access_tokens используется гемом doorkeeper собственно для хранения токенов. И этот запрос должен быть быстрым, ведь он используется при каждой аутентификации клиента.
Призвали на помощь explain analyze и удивились еще больше:
Gather (cost=1000.00..18279.52 rows=1 width=257) (actual time=196.940..204.560 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on oauth_access_tokens (cost=0.00..17279.42 rows=1 width=257) (actual time=190.088..190.165 rows=0 loops=3)
Filter: ((token)::text = 'eyJraWQiOiJvSGxKcW…cg'::text)
Rows Removed by Filter: 74906
Planning Time: 1.183 ms
Execution Time: 204.599 msНашли в коде приложения следующую миграцию:
def change # слишком большого размера получаются токены, постгрес не может их индексировать # если в будущем возникнет проблема с производительностью, то надо допилить гем remove_index :oauth_access_tokens, :token, unique: true remove_index :oauth_access_tokens, :refresh_token, unique: true end
После пыток паяльником автора этих строк было выяснено, что в связке с doorkeeper используется гем doorkeeper-jwt для трансформации обычного токен в jwt. Это необходимо для того, чтобы можно было в тело jwt нашего приложения положить токен полученный от гос сервиса, а также иную требующуюся информацию.
И в некоторых случаях размер jwt оказывался слишком большим и postgres не мог построить индекс. В моменте было принято решение не разбираться и удалить индекс.
ERROR: index row size 2904 exceeds btree version 4 maximum 2704 for index "index_oauth_access_tokens_on_token" DETAIL: Index row references tuple (1,9) in relation "oauth_access_tokens". HINT: Values larger than 1/3 of a buffer page cannot be indexed. Consider a function index of an MD5 hash of the value, or use full text indexing.
Решение проблемы
В целом, проблема найдена и она понятна, а самое главное, размер базы еще не увеличился до состояния, когда это будет аффектить работу приложения.
Интернеты предлагают несколько вариантов решения проблемы:
- переконфигурировать БД и увеличить размер блока
- сделать индекс по сгенерированному на лету хэшу значения
- изменить структуру таблицы БД и код приложения для работы только с хэшем токена
Первый вариант был отвергнут, как опасный и костыльный.
Выбрали второй, написали миграцию, накатили на тестовый стенд:
<<~SQL.squish CREATE UNIQUE INDEX CONCURRENTLY IF NOT EXISTS index_oauth_access_tokens_on_token ON oauth_access_tokens USING btree (encode(sha512(token::bytea), 'hex')); SQL
И вроде все хорошо, при создании нового токена, проверка на уникальность и правда работает:
EXPLAIN ANALYZE INSERT INTO oauth_access_tokens (token) VALUES ('eyJraWQiOiJvSGxKcWxiUEM…cg);
ERROR: duplicate key value violates unique constraint "index_oauth_access_tokens_on_token"
DETAIL: Key (encode(sha512(token::bytea), 'hex'::text))=(facef61…3346a) already existsПроверяем графики нагрузки на БД, а там без изменений. Красный iowait продолжает наступать. Топ тяжелых запросов к БД не изменился. Результаты explain analyze также не изменились. Провал по всем фронтам.
Оказалось индекс от хэша значения работает только для записи, но не для чтения. А чтение по базе токенов мы довольно часто используем, например:
- при каждом запросе для аутентификации клиента
- при каждом создании нового токена (благодаря валидации поля в моделе doorkeeper)
Про второй пункт немного подробнее. У doorkeeper модели есть валидация поля token. И перед каждым созданием токена происходит проверка на отсутствие такого значения в БД.
validates :token, presence: true, uniqueness: { case_sensitive: true }По итогу пришлось выбрать третий пункт, а именно добавить новое поле в модель doorkeeper и таблицу БД. Значение нового поля это SHA512 от обычного jwt.
Немного дописали код гема для генерации и поиска записи в БД:
def generate_token token = super secret_strategy.store_secret(self, :token_sha512, Digest::SHA2.new(512).hexdigest(token)) token end
def self.by_token(token) find_by_plaintext_token(:token_sha512, Digest::SHA2.new(512).hexdigest(token)) end
add_column :oauth_access_tokens, :token_sha512, :string, if_not_exists: true add_index :oauth_access_tokens, :token_sha512, unique: true, if_not_exists: true
Итоги
Для клиента ничего не изменилось, он как работал с токеном, так и работает. А под капотом приложение работать с проиндексированным хэшем от токена.
Jwt позволяет отказаться от хранения в БД совсем. Проверять подпись jwt и получать все данные из него. Для клиента, опять же, ничего не изменится.
Индекс по хэшу является переходным этапом и необходимо брать от jwt максимум, но это уже совсем другая история…