Prometheus

В интернетах легко можно найти статьи о том, как из Ruby on Rails приложения отдавать метрики в формате, совместимом с Prometheus, и есть готовая библиотека Prometheus::Client, которая решает эту задачу. Однако, если вы делаете не какую-то курсовую работу или простенький MVP проект, то вы обнаружите, что в реальном боевом продакшене кишки намотает на вентилятор всё не так просто. Вот об этом я расскажу в статье и в конце дам ссылку на шикарнейший гем :)
Ruby on Rails и все-все-все
Сначала давайте опишу, что есть "Ruby on Rails приложение в боевом продакшене", и как мы в RNDSOFT это понимаем. Приложение - это не только процесс, который обслуживает HTTP-запросы, это еще и отдельные процессы и сервисы, исполняющие фоновые задачи (ActiveJob), выполняющие дополнительную логику - например слушающие RabbitMQ очереди или Kafka топики, а также всякие фоновые штуки, вроде очистки или архивации. И конечно в современном мире это всё упаковано в Docker-контейнеры, исполняется в распределённой инфраструктуре и оркестрируется оркестратором. Почему же это называется Rails-приложением? Да потому что всё это имеет единую кодовую базу, БД, использует все подсистемы Rails да и запускается зачастую через rails runner ./jobs.rb. Итого в нашем приложении есть:
- Rails web-сервер. В нашем случае это Phusion Passenger в multiprocess режиме;
- Фоновые (отложенные) задачи ActiveJob. В нашем случае на базе DelayedJob;
- Дополнительный “НЕ HTTP” сервис (запуск через
rails runner). У нас зачастую это RabbitMQ слушатель; - cron-сервис, выполняющий регулярные задачи вроде экспорта статистики. Мы для этого используем Rufus Scheduler. Про Rufus я писал раньше и статья не потеряла актуальности;
Само собой, что все эти сервисы запущены не в единственном экземпляре и размазаны по нескольким виртуалкам (для оркестрации мы используем Nomad, но это уже совсем другая история (c)).
Сразу к проблемам - от простых к сложным
- Фоновые задачи и другие “НЕ HTTP” сервисы не имеют HTTP-интерфейса для того, чтобы Prometheus мог собрать (scrape) с них метрики;
- Прометеевские счётчики хранятся в памяти процесса, и поэтому с multiprocess или pre-fork серверов не так просто собрать эти метрики. Сюда попадает наш любимый Passenger, Puma (в кластерном режиме) да и любой другой Rack-херак сервер, который порождает внутри себя процессы;
- DelayedJob, являясь однопоточным, в базовом варианте лишен предыдущего недостатка, но мы в целях оптимизации и ускорения используем Delayed Job Worker Pool, который внутри себя порождает пул процессов, обрабатывающих задачи, и проблема встаёт в полный рост;
- Ну и теперь вишенка (на решение которой и направлена эта статья) - вытекает из пунктов 2 и 3 - структура хранения данных счётчиков прометея забивает диск числом файлов, что сильно сказывается на производительности, особенно если вы редко рестартуете (например деплоите) приложение.
Проблема 1 - “у меня в сервисе нет HTTP!”
Тут всё просто - запускайте в сервисе простой Rack-сервер (обычного WebBrick хватит с головой) и экспортируйте метрики, как белые люди . Если кто-то хочет предложить "push-gateway или его аналог" - пусть отправляется гореть в Ад 😈вместе с этим самым "push-gateway или его аналогом". Спрашивайте отдельно, почему так… Если не боитесь…
Проблема 2 - multiprocess и pre-fork и прочие cluster-mode
В этом вопросе сосредоточен основной корень проблемы, я постараюсь описать его подробно. Схему в студию!
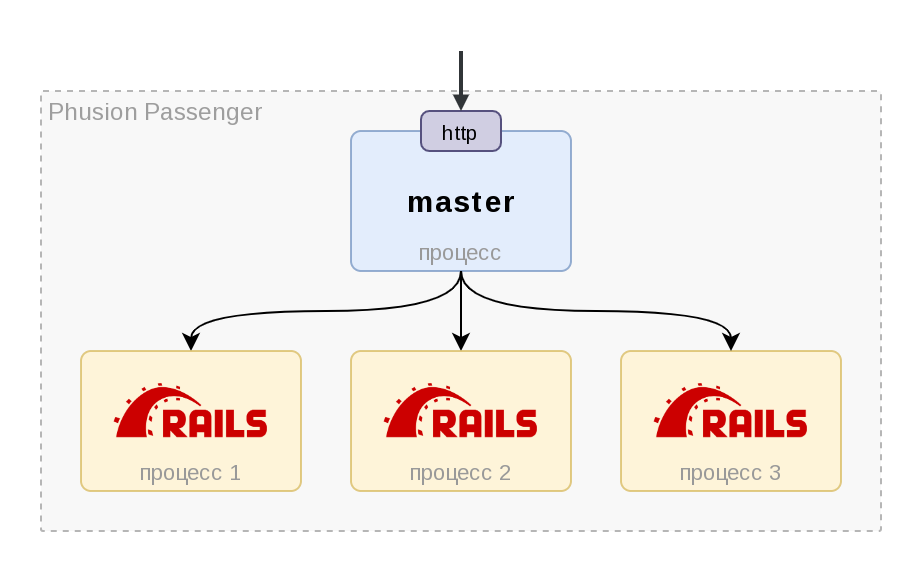
Итого, на схеме видно, что мы имеет 1 мастер-процесс (в случае Passenger Standalone это модифицированный Nginx), который принимает запросы, спавнит/форкает в отдельных процессах Rails-приложения и отдаёт им запрос на обработку. А сами счётчики-то находятся в памяти Rails-приложения, и каждый форк имеет только свой счётчик, ничего не зная о соседях. Когда прилетает scrape-запрос на сбор метрик, он попадает в какой-то один процесс и не может отдать результат, накопленный другими.
💡 Есть проблема - есть решение! Разработчики библиотеки Prometheus::Client - не дураки, и предусмотрели это через абстракцию Data Store, которая отвечает за хранение метрик. По умолчанию используется DataStores::Synchronized, которая работает в однопроцессном приложении и хранит данные в памяти, но есть и готовая реализация DataStores::DirectFileStore. Поскольку все порождённые процессы разделяют общую файловую систему, то нет никаких проблем (почти, но об этом в пункте 4) синхронизировать счётчики между ними. Именно этим и занимается DirectFileStore - хранит данные счётчиков на файловой системе. И когда любой из Rails-процессов получает на обработку scrape-запрос, он спокойно собирает все метрики (свои и своих соседей) и отдаёт их. ✅ Проблема решена.
Проблема 3 - DelayedJob и Pool процессов
Тут тоже всё просто как в первой проблеме - запускаем простенький Rack-сервер прямо внутри DelayedJob через его систему плагинов или в master-процессе, если вы используете Delayed Job Worker Pool. Затем, как в проблеме 2, используется DirectFileStore. ✅ Проблема решена.
Проблема 4 - если всё хорошо, то почему всё плохо?
В этом разделе нам придётся немного погрузиться в потроха DirectFileStore, в то, как он хранит данные на диске. А раз к данным имеют доступ несколько процессов, то быть беде: вас ожидают гонки и конкуренция. Погнали!
Допустим процесс 1 (из первой схемы) хочет сохранить значение своего счётчика, процесс 2 страстно желаете того же. Как же им записать это всё в файл и не затереть данные друг друга? К этому надо добавить еще оптимизацию структур данных, чтоб не тормозила ни запись, ни чтение. Можно конечно использовать какие-то блокировки, но это зашквар - метрики не должны влиять на производительность приложения и задержки. Разработчики библиотеки Prometheus::Client использовали хорошее решение - каждый процесс пишет данные строго в свой файл, и таким образом, нет никакой конкуренции. Процесс, который читает сразу из всех файлов (по маске), ведь оно ему так и положено - отдавать данные всех соседей. А как процессам узнать, какой файл их лично-персональный? Достаточно просто - надо использовать PID своего процесса в качестве составной части имени файла:
prometheus_metrics/ ├── metric_http_server_request_duration_seconds___18072.bin ├── metric_http_server_requests_total___18072.bin ├── metric_sql_query_duration___18072.bin ├── metric_http_server_request_duration_seconds___18054.bin ├── metric_http_server_requests_total___18054.bin └── metric_sql_query_duration___18054.bin
Всё работает на ура. Но внимательный 👀 и дотошный разработчик сразу почувствует тут неладное… Почувствовали? Вот и мы не сразу почувствовали…
Что будет с этими файлами, если ваш контейнер проработает без перезапусков, например, неделю? Будет сральник! У нас ведь multiprocess/pre-fork сервер, и он периодически порождает новые процессы и убивает старые, и вы легко получите несколько тысяч таких файлов за неделю. А если у вас зрелое приложение, обмазанное метриками с ног до головы, то и несколько сотен тысяч файлов. А бедный процесс, которому выпало счастье отрендерить ответ на scrape-запрос, вынужден прочитать все эти файлы и агрегировать данные… Раз за разом… Снова и снова... Каждые 30 секунд… Как вспомню, так вздрогну.
Какой же выход? Неужели придётся продать душу и использовать push-gateway? Хрен там плавал!
Решение
pre-fork, не pre-fork в каждый момент времени (внутри одного контейнера) у вас не так много процессов - обычно от 2х до 10ти - если надо больше, то вы скорее всего будете масштабироваться контейнерами. Кроме того, запуск/остановка процессов достаточно редкое явление - мы у себя используем настройку Passenger "max_requests": 4000 - то есть каждый наш процесс будет перезапускаться через каждые 4000 запросов. На проде под нагрузкой это происходит примерно каждые 15 минут - ооочень редко. Таким образом, можно развить идею лично-персональных файлов по принципу "рассчитайсь!", не сильно заботясь о накладных расходах.
Алгоритм: процесс при старте анализирует запущенные процессы и выбирает свой порядковый номер - 1, 2, 3 и т.д. Если "первому" пришла пора завершиться, то его место освобождается, и следующий может занять его. Этот идентификатор теперь надо использовать вместо PID-процесса в имени файла. Готово!
Осталось решить небольшую проблему, а именно синхронизацию процесса выбора номера. Тут именно из-за редкости перезапуска можно использовать межпроцессные блокировки, они не окажут никакого влияния на производительность, поскольку выполняются только 1 раз при старте процесса (как мы выяснили не чаще 1 раза в 15 минут). Встречаем системный вызов flock! Теперь можно перейти к коду.
# Собственно блокировка
def with_lock
File.open(lock_path, File::RDWR | File::CREAT, 0o644) do |file|
file.flock(File::LOCK_EX)
Dir.chdir(@dir) do
tmpfilename = ".tmp-#{$}-#{rand(0x100000000).to_s(36)}.json"
yield(tmpfilename)
ensure
File.delete(tmpfilename) rescue nil
end
end
end
# Ну и весь процесс
def obtained
@obtained ||= with_lock do |tmpfilename|
raw_data = read_instances
data = JSON.parse(raw_data) || {}
data = clean_dead_instances(data)
obtain_instance_number(data)
File.write(tmpfilename, data.to_json)
File.rename(tmpfilename, @instances_path)
end
end- процесс захватывает блокировку;
- читает файл, где процессы распределили номера между собой в формате
{pid => порядковый номер}.Например:{18054=>0; 18072=>1}; - занимает следующий номер;
- чистит номера, процессы которых уже умерли;
- переписывает файл;
- отпускает блокировку.
Есть несколько неочевидных моментов, на которые хочу обратить внимание, поскольку они могут попортить вам кровь.
Запись в файл данных - операция не атомарная
Таки да - если с вами (имеется в виду ваш процесс) что-то случится, то файл останется битый, другие процессы не смогут его прочитать, всё сломается и приведёт к отказу в лучшем случае метрик, в худшем - к краху приложения (да, такое у нас бывало). А вот операция переименования - атомарна, поэтому мы пишем данные в новый временный файл, а потом переименовываем его в целевой.
Моё второе имя - скорость!
Для того, чтобы flock был еще более быстрый, чем он есть, мы через оркестратор монтируем tmpfs в каждый контейнер, и в данном случае как сами метрики, так и файл с блокировкой находится в tmpfs.
It's Alive!!!
Проверить, жив процесс или нет, можно по пиду:
def alive?(pid) return nil if pid <= 1 Process.getpgid(pid) true rescue Errno::ESRCH false end
Monkeypatching
К сожалению, DataStores::DirectFileStore не рассчитан на наследование и переопределение метода формирования имени файла, но у нас старый добрый Ruby, в котором есть monkeypatching:
class Store < Prometheus::Client::DataStores::DirectFileStore
attr_reader :pid_enumerator
def initialize(*_args, dir:, **_kwargs)
super
@pid_enumerator = PidEnumerator.new(dir: dir)
@store_settings[:pid_enumerator] = @pid_enumerator
end
MetricStore.class_eval do
# Monkeypatch! there is no normal method to overload filename generation
def process_id
@store_settings[:pid_enumerator].obtained
end
end
end🍒 Но вам не стоит об этом беспокоиться - мы сделали для вас гем и внимательно следим за его совместимостью!
Перед списком литературы
Я понял, что пишу статью, чтоб скорее перейти к списку литературы... Но сначала небольшой итог. Мы не используем push-gateway или промежуточные экспортеры, мы отдаём метрики прямо из наших контейнеров/сервисов. Это очень удобно и максимально надёжно. Описанное выше решение работает в распределённой нагруженной системе больше года - пользуйтесь! Наконец-то:
- flock(2) — Linux manual page - Системный вызов flock;
- Delayed Job Queue Fairness - шикарная статья от Salsify про Fair queuing (даже затрудняюсь перевести, но очень интересно);
- Delayed Job vs. Sidekiq - простенькое сравнение, но прочитать можно;
- Phusion Passenger Design and Architecture - для суровых мужиков.