GIT, как это развидеть?

GIT — замечательная система для хранения говнокода информации, но что если надо информацию из неё удалить, да так, чтобы никто и никогда её не нашел? А что если в проблему вмешивается GitLab со своими скрытыми ссылками? В статье будет боль и немного полезных git-команд.
Однажды, новый заказчик попросил копию исходного кода нашего старого и уважаемого продукта «чтобы было». Я поленился гуглить, как там правильно вызывать git archive (а надо вот так git archive -o latest.zip HEAD), а потому решил склонировать репозиторий в /tmp и запаковать руками.
Каково же было мое удивление, когда при клонировании начало стягиваться более 400 Мб. Проект, как я уже говорил, старый и уважаемый, но не настолько. Вот тут уже пришлось все-таки начать гуглить, а как, собственно, узнать, кто у нас такой упитанный?
Гугл выдал широкоизвестную в узких кругах команду:
git rev-list --objects --all | git cat-file --batch-check='%(objecttype) %(objectname) %(objectsize) %(rest)' | sed -n 's/^blob //p' | sort --numeric-sort --key=2 | cut -c 1-12,41- | $(command -v gnumfmt || echo numfmt) --field=2 --to=iec-i --suffix=B --padding=7 --round=nearest
Меньше минуты и передо мной список виноватых:
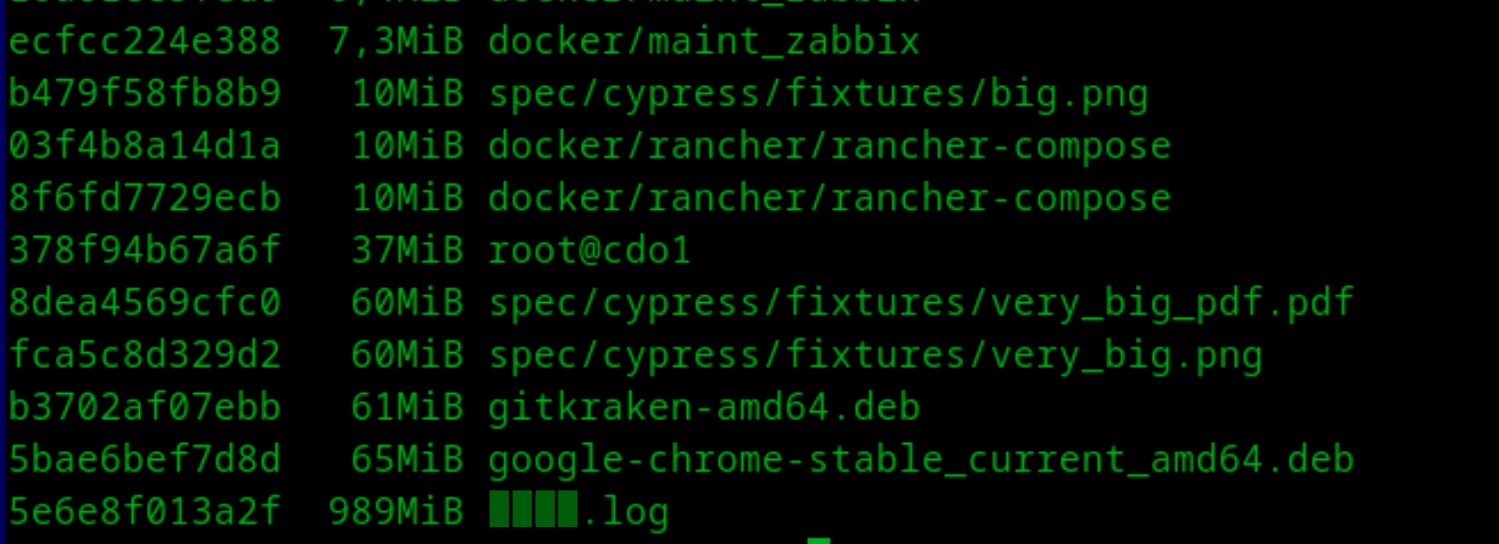
Очень показательный список, покрывающий самые частые причины появления странных файлов в репозиториях. Начнем сверху:
root@cdo1— явно причина опечатки в длинной консольной команде, где перенаправление потока на удаленный сервер перенаправило поток в файл;very_big*— товарищ автоматизатор захотел начать тестировать ограничение на размер загружаемых пользователем файлов. Все бы ничего, но файл бинарный, а значит практически не жмётся. Сразу скажу, что по итогу заменил содержимое на 62 миллиона единиц и получил практически нулевой размер в репозитории;gitkraken-amd64.deb— когда идешь по How to install обычно на подумать времени не остается, и команды исполняются в первой попавшейся консоли, а там почти всегда открыт проект. Мы ж на работе сидим, а тут не модно держать консоли открытыми в нерабочих местах;- Ну и самое вкусное —
████.log. Причина появления этой статьи.
Это уже кое-что действительно серьезное. И даже не потому, что он весит почти гигабайт. Дело в том, что это журнал доступа к объекту класса Кетер, который программист слил из зоны содержания для [ДАННЫЕ УДАЛЕНЫ], а после того, как исправил код, быстренько сделал git commit -am "my awesome fix" и побежал гонять кофеи. И пока нас всех за такое не перевели в сотрудники класса D, надо бы от этого суперсекретного журнала избавиться, чтоб никто и никогда не нашел.

Программист видимо решил также, и после того как попил кофе, увидел свою оплошность, удалил файл и сделал новый коммит. Казалось бы всё логично, но проблема в том, что GIT - это дедушка этих ваших блокчейнов и все изменения оставляет в своей цепочке связанных коммитов. Удаление из репозитория - это просто инструкция удаления файла внутри нового коммита. Откатились назад по истории и вуаля — файл снова на месте.
А значит нам надо переписать историю!

Для этого нужно найти коммит, где добавлен проблемный файл и убрать из него этот файл. Ну и вспоминая знаменитую сцену с линиями времени из «Назад в будущее 2», из-за этого перепишется вся история коммитов, так как их хэши взаимосвязаны. Как я и говорил — блокчейн жалкое подобие GIT’а. МаскТорвальдс гений!
Итак, давайте найдем коммиты, в которых записывался и удалялся наш файл. Как видим из вывода команды со списком виноватых идентификатор проблемного файла в GIT 5e6e8f013a2f. Выполняем команду:
git log --pretty=format: %H — ./ | xargs -I% sh -c "git ls-tree % — ./ | grep -q 5e6e8f013a2f && echo %"
И на выходе получаем хэши коммитов
148109d10cb30cb6b8acaf39c6c51268efa0fcfe
555935f1d822189bb9712f1dc3f30932e692101c
Если взглянуть на их содержимое, то будет видно, что в первом файл попал в историю, а во втором он удален. Но это естественно было бесполезно.
Один из способов исправления подобного - это git rebase -i 148109d10cb30, при котором GIT вернет нас на нужный коммит, даст его изменить, а затем последовательно применит все последующие коммиты с пересчетом их хэшей. Затем git push -f и добро пожаловать в альтернативную вселенную, где никто никакие журналы никуда не скачивал.
Но есть проблема: сделать это надо в каждой ветке, которая отделялась после злополучного коммита. Иначе GIT сдвинет точку отделения до переписанного коммита 148109d10cb30 и в ветке останется возможность найти злополучный журнал.
Проблема усложняется ещё и тем, что основной репозиторий у нас GitLab, а он делает целую гору ссылок, тегов, скрытых веток для реализации всех тех удобностей, к которым мы так привыкли: merge requests, pipelines, issues, ссылок между ними в интерфейсе и прочего.
Что же делать? Оказалось, что как и в моем DOOM’ном детстве, многие проблемы может решить BFG.

Кстати, у нас есть статья о том, как вставить DOOM в ваш проект
Но, к сожалению, этот BFG не превращает демонов в облако кровавой пыли. Он написан на Java и по паспорту зовется BFG Repo-Cleaner.
Кроме BFG, для любителей python есть ещё git-filter-repo, но он работает существенно медленнее BFG — в моем случае git-filter-repo отрабатывал больше часа против нескольких минут у BFG.
git clone --mirror git@company.url:project.git java -jar /tmp/bfg-1.14.0.jar --strip-blobs-bigger-than 15M --no-blob-protection project.git cd project.git git reflog expire --expire=now --all && git gc --prune=now --aggressive git push -f
и мы спасены! Файла больше нет нигде, а слитый репозиторий похудел до приемлемой сотни мегабайт.
Но, к сожалению, полноценно сохранить все связи во внутренней кухней GitLab с помощью BFG у меня так и не получилось. Пуш исправленного репозитория неизменно приводил к подобному
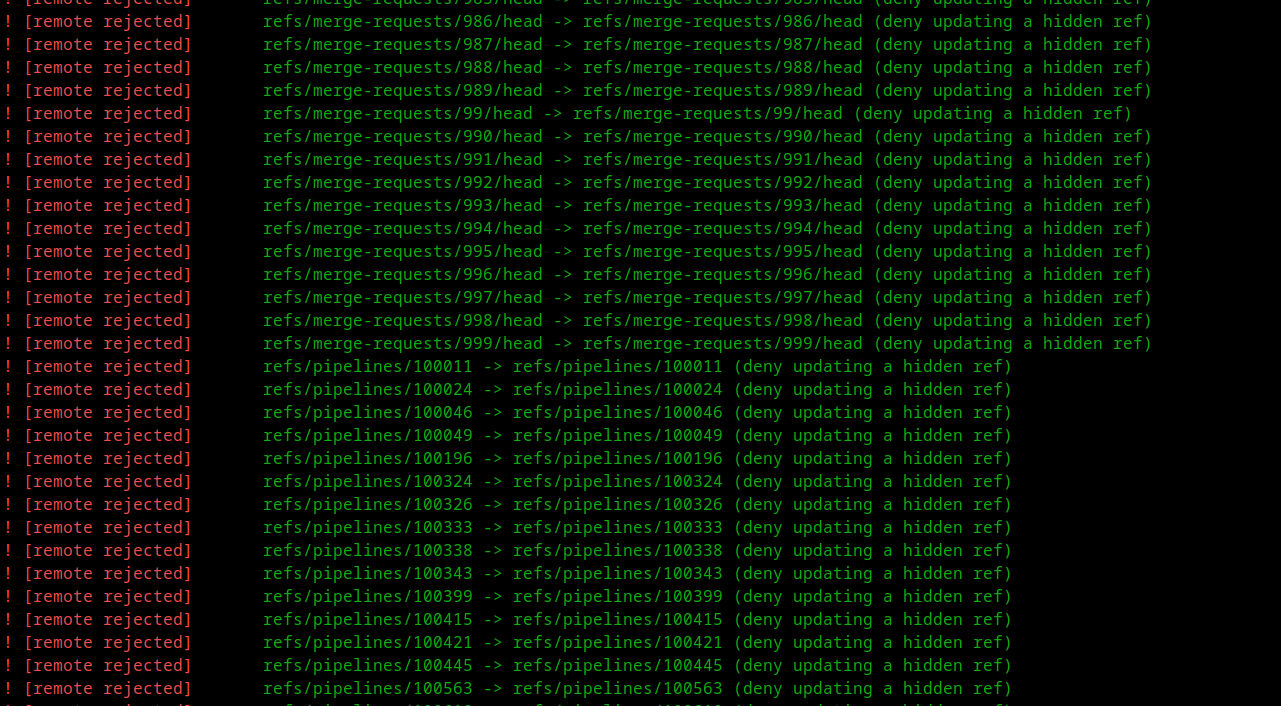
В поисках решения я натыкался на разные способы, например, такие на StackOverflow. Но в моем случае внятного улучшения результата ни один из них не дал — связи все равно терялись, либо (что хуже) файл оставался в репозитории. Я только угробил тонну времени на каждый из них, так как обработка репозитория занимала обычно несколько часов.
В итоге было принято волевое решение забить на потерянные связи. Как показала практика, мы потеряли только ссылки на МРы из коммитов сделанных после проблемного. Но у нас к тому времени уже была внедрена практика указывать в каждом коммите номер задачи, в рамках которой он сделан, так что возможность искать концы в истории коммитов осталась, пусть и не такая удобная как раньше.
В заключении скажу, что крайне полезно иногда пробегаться по только что слитому проекту в поисках вот таких вот артефактов. Уверен, вы сможете найти там если не секретный журнал, то не менее секретный токен или пароль от какого-нибудь внешнего сервиса. Когда-нибудь каждый программист начнет строго следовать рекомендациям старого советского плаката, и мир станет безопаснее, а пока — держите ваш BFG под рукой.
