Простейший AI ассистент или Tools or not tools
Нужно бежать со всех ног, чтобы только оставаться на месте, а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее! Льюис Кэролл Алиса в Cтране Чудес

В данной статье мы продемонстрируем, как можно построить простейшего AI ассистента. Давайте сперва определимся с терминами. Обычно под AI ассистентом подразумевают способности Больших языковых моделей (далее по тексту LLM) не просто выдавать готовый текстовый ответ, но и совершать какую-то автономную работу по вызову сторонних функций, отправку запросов в API и на основании полученной информации из сторонних сервисов (но иногда нужно получить именно точный ответ в заданном формате), промпта, а также запроса пользователя выдавать итоговый ответ. Так, с терминами определились. Теперь вкратце о чем будет статья: в статье мы покажем, как 2мя способами LLM заставить взаимодействовать с внешним миром и с информацией, полученной не от пользователя, а из внешнего мира. В данной статье мы будем обогащать вывод LLM информацией из поиска, т.к. основной проблемой LLM является то, что в них информация заморожена на определенный момент времени, и с течением времени она устаревает и требует переобучения модели. Переобучение модели является очень дорогостоящим мероприятием, т.о. чтобы актуализировать информацию можно делать запросы в интернет, чтобы получать свежую информацию, а LLM будет нам, используя информацию из своего пространства знаний, а также дополняя информацией из поиска, выдавать достаточно свежий результат. На основе скриптов из этой статьи можно будет уже делать первые попытки для построения собственных мини-ассистентов.
Инструменты
В данной статье будут использованы следующие технологии:
- В качестве поискового движка будем использовать Tavily, т.к. у него простое API, а также они заявляют, что оптимизируют свой поиск как раз для использования с LLM (подробней можно почитать в документации к tavily)
- LLM YandexGPT 4 Pro 32k RC
- Python, Gradio
Нужно получить API ключи для YandexGPT API и ключ для Tavily
Промптинг
В первом способе будем использовать результаты вызова функции в промпте для получения окончательного ответа от LLM как самый примитивный способ.
Ниже представлен код скрипта yc-search-prompt.py
#!/usr/bin/env python3
import httpx
import os
import gradio as gr
from tavily import TavilyClient
BASE_YC_GPT_URL = "https://llm.api.cloud.yandex.net/foundationModels/v1/completion"
def format_search_results(search_results):
formatted_results = "\nRelevant search results:\n"
for result in search_results['results']:
formatted_results += f"- {result['title']}: - URL: {result['url']} \n {result['content'][:200]}...\n"
def create_prompt_with_search(user_message, search_results):
search_context = format_search_results(search_results)
prompt = f"""Here is some relevant context from a web search:
{search_context}
Using the above context, please answer the following question:
{user_message}
Please provide a comprehensive answer based on both the search results and your knowledge.
And add at the end of final answer all titles and URL links at format Title - Url from above context."""
return prompt
def make_search_request(text):
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"] )
response = tavily_client.search(text, max_results=8)
return response
def make_request_yc_gpt(text, history):
with httpx.Client() as client:
headers = {'Authorization': "Api-Key " + os.environ['YC_API_KEY'],
'content-type':'application/json'}
r = client.post(BASE_YC_GPT_URL, timeout=None,
json={"modelUri": "gpt://"+os.environ['YC_FOLDER_ID'] + "/yandexgpt-32k/rc",
"completionOptions": {
"stream": False,
"temperature": "0.3",
"maxTokens": "2000"
},"messages": [{"role": "user","text": text}]}, headers=headers)
return r.json()["result"]["alternatives"][0]["message"]["text"]
def chatbot_function(message, chat_history, model_choice):
try:
if model_choice == "YandexGPT+Tavily":
search_results = make_search_request(message)
enhanced_prompt = create_prompt_with_search(message, search_results)
print(enhanced_prompt)
bot_message = f"You selected the {model_choice} model.\n" + make_request_yc_gpt(enhanced_prompt, chat_history)
chat_history.append((message, bot_message))
else:
bot_message = f"You selected the {model_choice} model.\n" + make_request_yc_gpt(message, chat_history)
chat_history.append((message, bot_message))
return "", chat_history
except Exception as e:
error_message = f"An error occurred: {str(e)}"
chat_history.append((message, error_message))
return "", chat_history
with gr.Blocks() as demo:
gr.Markdown("AI prompting with internet search")
with gr.Row():
with gr.Column(scale=4):
chatbot = gr.Chatbot()
msg = gr.Textbox(label="Сообщение")
submit = gr.Button("Отправить")
clear = gr.Button("Очистить")
with gr.Column(scale=1):
model = gr.Radio(
["YandexGPT+Tavily", "YandexGPT"],
label="Выберите модель",
value="YandexGPT+Tavily"
)
submit.click(chatbot_function, inputs=[msg, chatbot, model], outputs=[msg, chatbot])
msg.submit(chatbot_function, inputs=[msg, chatbot, model], outputs=[msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
demo.launch()
Примечание: Помните: при запросах к YandexGPT и Tavily могут списываться денежные средства. Перед запуском скрипта читайте актуальные правила использования сервисов.
Запускать скрипт следующим образом
YC_FOLDER_ID=folder_id YC_API_KEY=YANDEX_API_KEY TAVILY_API_KEY=TAVILY_KEY python3 yc-search-prompt.py
Принцип работы скрипта: В UI Gradio на вход скрипт принимает текст от пользователя, в зависимости от того выбран ли вариант использования вместе с Tavily (YandexGPT+Tavily), тогда отправляется запрос в поиск Tavily, потом результат поиска отдается YandexGPT с промптом и просьбой сформировать окончательный ответ из собственных знаний, а также результатов поиска, а также в ответ добавить ссылки на источники из поиска.
Function calling (Tools)
Второй способ также будет использовать промпт для получения окончательного ответа, но для получения результатов поиска мы будем использовать функционал function calling. Наверное стоит остановиться подробней, для чего это нужно, т.к. кода стало почти в 2 раза больше, а результат такой же. Function calling (Tools) - это способность LLM вызывать сторонние приложения, это могут быть скрипты, обращения к различным API. В большинстве случаев это необходимо, когда для LLM нужно получить конкретный ответ (конечно, пример с использованием поиска не очень подходящий, но хотелось сделать примеры максимально похожими, больше здесь подходит, например, вызов функции, которая использует калькулятор), что-то посчитать, а т.к. LLM не предназначены для конкретных вычислений, то для этого используется функционал function calling. При этом если Tools будет много, то LLM может и сама принимать решение, когда и какой Tool ей вызывать (у anthropic есть прямо определение поведения LLM для выбора Tools. Важный момент: нужно делать хорошее описание для tools. Вот примеры хороших и плохих описаний tools от одного из лидеров индустрии.
- в YandexGPT API на момент написания статьи функционал Tools находился в режиме бета-тестирования, может быть непредвиденное поведение.
- На момент написания статьи в скриптах использовалась версия релиз кандидат YandexGPT RC 32k, подробней про жизненный цикл моделей читайте в документации
Ниже представлен код скрипта yc-search-tools.py
#!/usr/bin/env python3
import httpx
import os
import json
from tavily import TavilyClient
import gradio as gr
BASE_YC_GPT_URL = "https://llm.api.cloud.yandex.net/foundationModels/v1/completion"
search_tool = {
"function": {
"name": "search_tavily",
"description": "Search the web for current information",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query"
}
},
"required": ["query"]
}
}
}
def format_search_results(search_results):
formatted_results = "\nRelevant search results:\n"
for result in search_results['results']:
formatted_results += f"- {result['title']}: - URL: {result['url']} \n {result['content'][:200]}...\n"
return formatted_results
def create_prompt_with_search(user_message, search_results):
search_context = format_search_results(search_results)
prompt = f"""Here is some relevant context from a web search:
{search_context}
Using the above context, please answer the following question:
{user_message}
Please provide a comprehensive answer based on both the search results and your knowledge.
And add at the end of final answer all titles and URL links at format Title - Url from above context."""
return prompt
def make_request_yc_gpt(text, is_tool_call=True):
with httpx.Client() as client:
headers = {'Authorization': "Api-Key " + os.environ['YC_API_KEY'],
'content-type':'application/json'}
payload = {
"modelUri": f"gpt://{os.environ['YC_FOLDER_ID']}/yandexgpt-32k/rc",
"completionOptions": {
"stream": False,
"temperature": 0.0,
"maxTokens": 8000
},
"messages": text
}
if is_tool_call:
payload["tools"] = [search_tool]
r = client.post(
BASE_YC_GPT_URL,
timeout=None,
json=payload,
headers=headers
)
response = r.json()
return response
def handle_tool_calls(toolCalls):
results = []
for tool_call in toolCalls:
if toolCalls[0]["functionCall"]["name"] == "search_tavily":
result = make_search_request(tool_call["functionCall"]["arguments"]["query"])
return result
def make_search_request(text):
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"] )
response = tavily_client.search(text, max_results=8)
return response
def process_conversation(user_input, history):
conversation = [
{
"role": "system",
"text": "You are a helpful bot that helps the user. You can use tools at your discretion to generate answers, but you don't always need to use them."
},
{
"role": "user",
"text": user_input
}
]
initial_response = make_request_yc_gpt(conversation)
if "toolCalls" in initial_response['result']['alternatives'][0]['message']['toolCallList']:
tool_results = handle_tool_calls(
initial_response['result']['alternatives'][0]['message']['toolCallList']["toolCalls"]
)
enhanced_prompt = create_prompt_with_search(user_input, tool_results)
final_conversation = [
{
"role": "user",
"text": enhanced_prompt
}
]
final_response = make_request_yc_gpt(final_conversation, is_tool_call=False)
return final_response['result']['alternatives'][0]['message']['text']
else:
return initial_response['result']['alternatives'][0]['message']['text']
def chatbot_function(message, chat_history, model_choice):
try:
response_list = process_conversation(message, chat_history)
if isinstance(response_list, list):
formatted_responses = [item['text'] for item in response_list if isinstance(item, dict) and 'text' in item]
bot_message = f"You selected the {model_choice} model.\n" + "\n".join(formatted_responses)
else:
bot_message = f"You selected the {model_choice} model.\n" + str(response_list)
chat_history.append((message, bot_message))
return "", chat_history
except Exception as e:
error_message = f"An error occurred: {str(e)}"
chat_history.append((message, error_message))
return "", chat_history
with gr.Blocks() as demo:
gr.Markdown("AI function calling tools internet search")
with gr.Row():
with gr.Column(scale=4):
chatbot = gr.Chatbot()
msg = gr.Textbox(label="Сообщение")
submit = gr.Button("Отправить")
clear = gr.Button("Очистить")
with gr.Column(scale=1):
model = gr.Radio(
["YandexGPT+Tavily"],
label="Модель",
value="YandexGPT+Tavily"
)
submit.click(chatbot_function, inputs=[msg, chatbot, model], outputs=[msg, chatbot])
msg.submit(chatbot_function, inputs=[msg, chatbot, model], outputs=[msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
demo.launch()Примечание: Помните, при запросах к YandexGPT и Tavily могут списываться денежные средства. Перед запуском скрипта читайте актуальные правила использования сервисов.
Запускать скрипт следующим образом
YC_FOLDER_ID=folder_id YC_API_KEY=YANDEX_API_KEY TAVILY_API_KEY=TAVILY_KEY python3 yc-search-tools.py
Вкратце принцип работы скрипта: В UI Gradio на вход скрипт принимает текст от пользователя, вызывает tool tavily_search, после этого результаты поиска отдается YandexGPt с промптом и просьбой сформировать окончательный ответ из собственных знаний, результатов поиска, а также в ответ добавить ссылки на источники из поиска.
Итоги и дополнительные материалы
В итоге мы получили простенький аналог perplexity.ai, сделанный своими руками. Несколько скринов как это выглядит.
Ответ YandexGPT, дополненный информацией из Tavily
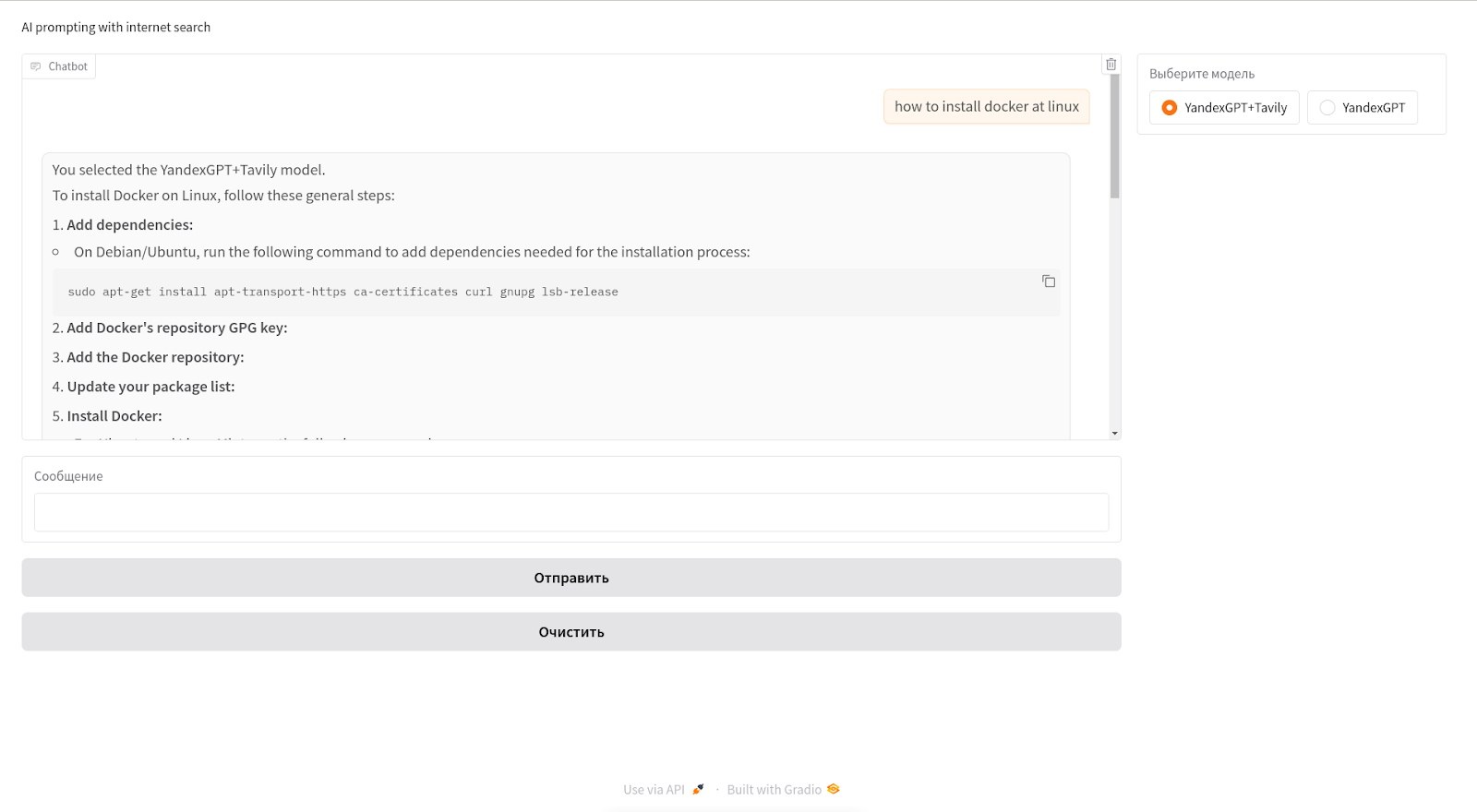
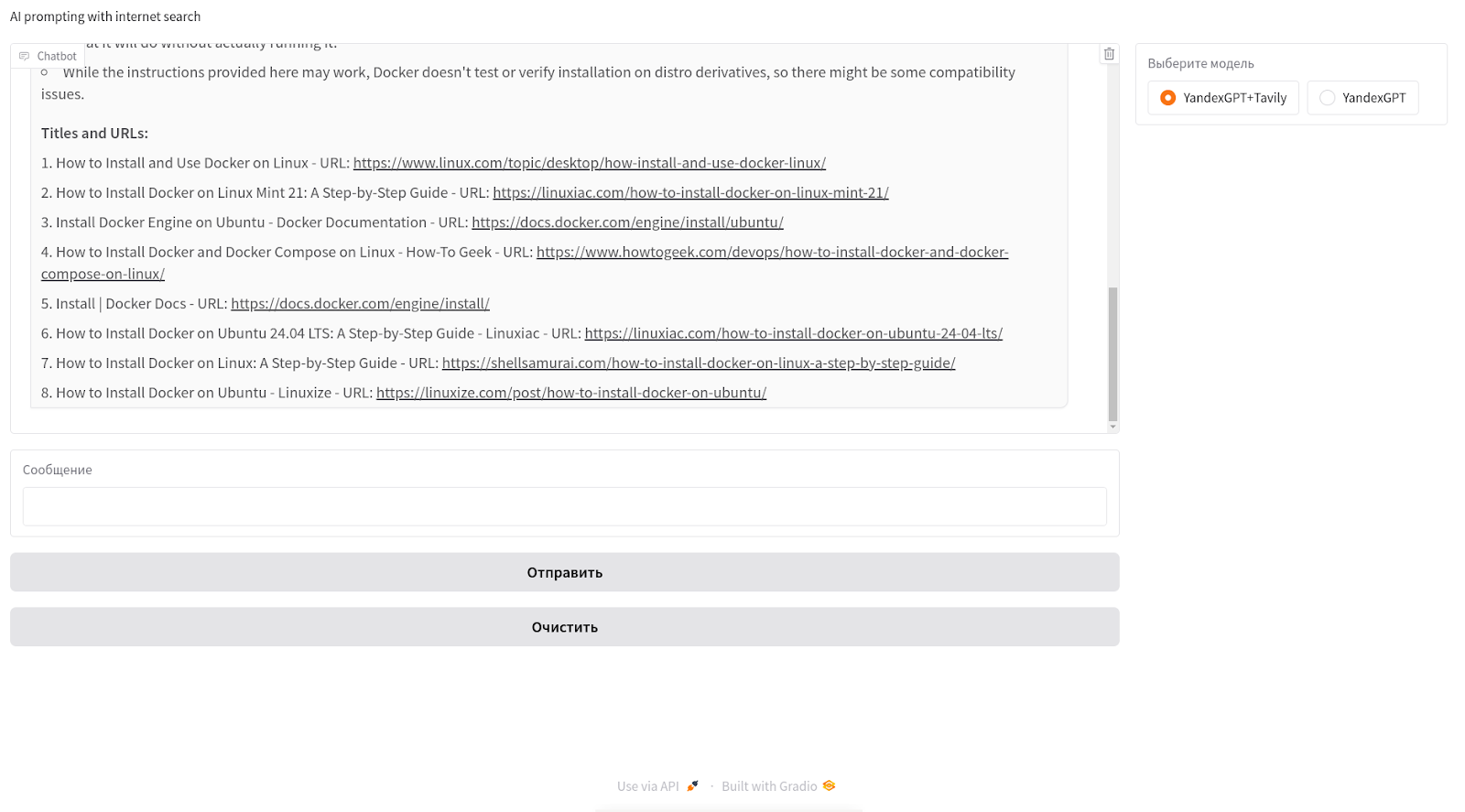
И ниже ответ дополняется ссылками (блок Titles and URLs) в поиске
Ответ YandexGPT без дополнения ответа результатами из поиска, как видно внизу без ссылок на результаты поиска

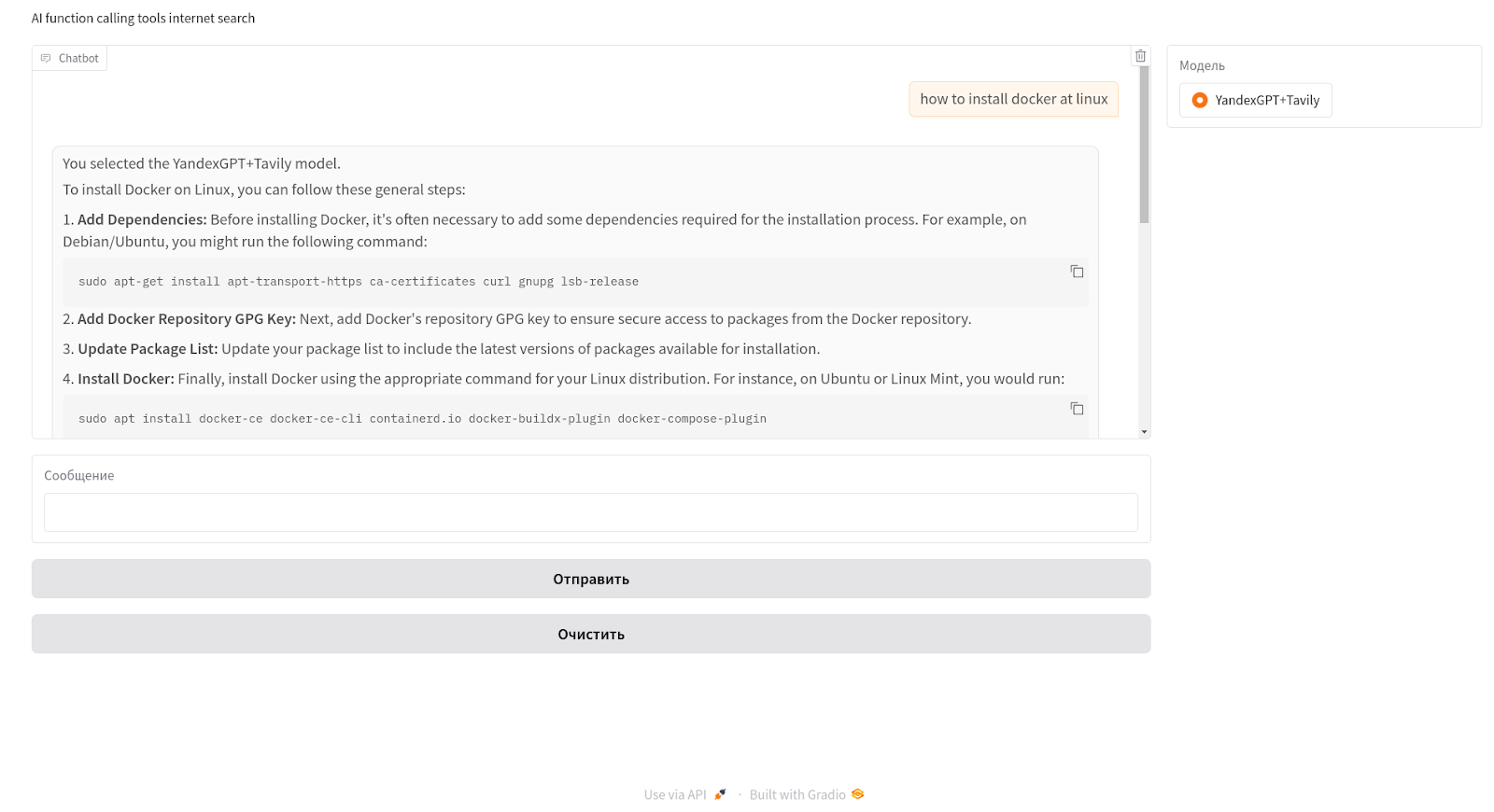
Приводим аналогичные скрины с использованием функционала Tools

Одним из самых частых препятствий в процессе промышленного внедрения LLM являются галлюцинации и проблемы получения конкретных ответов, и хочется сказать еще пару слов про библиотеки и фреймворки, которые могут быть полезны для решения этих проблем.
- Не пренебрегайте промптами, если у вас нет других инструментов для контроля LLM. Хороший материал на тему prompt engineering
- Кроме промптинга есть фреймворки для работы с промптами, например, dspy, к сожалению, из коробки поддержки YandexGPT там нет, но можно пробовать использовать адаптер для совместимости с OpenAI API + dspy (сами, честно говоря, еще не пробовали) и проголосовать за фичу в Yandex Cloud
- Помимо коммерческих реализаций есть также уже много open source моделей, в которых реализован функционал tools, например, у ollama. Кажется, скоро эта фича станет стандартной в LLM.
- Кроме промптинга есть еще возможность заставить LLM четко следовать формату ответа, это т.н. structured output, вот хорошая статья с библиотеками, большинство библиотек в этом списке тоже не поддерживают YandexGPT (а также почти все нестабильных версий 0.x.x), но чтобы этот мир стал еще лучше, можете проголосовать за эту фичу
- Фреймворки для построения агентов и мультиагентских систем
- LangGraph кандидат, чтобы стать стандартом в индустрии (там готовится целая экосистема библиотек для работы с LLM LangChain, LangSmith, LangGraph), самая большая поддержка различных LLM. Очень нестабильно. Но в документации к LangGraph можно почерпнуть много хороших идей для построения агентов Tutorials и How-To, это прямо must read! Для построения MVP и быстрого прототипирования подходит отлично.
- Llamaindex Тоже довольно большая библиотека для работы с LLM. Подробней что-то рассказать сложно, сами не пользовались.
- AutoGen библиотека для построения мультиагентских систем. Огромное кол-во примеров под разные use cases.
- Совсем недавно в Yandex cloud появился новый функционал AI assistant, который с использованием их ML SDK тоже позволяет строить LLM приложения и прячет некоторые вещи “под капот”, которые обычно используются в LLM приложениях: RAG, сохранение контекста.
- Также совсем недавно anthropic выпустил Model Context Protocol, для более глубокой интеграции LLM, tools и источников данных. Посмотрим, сможет ли MCP стать стандартом в будущем.
- Также аналогичный функционал, скорей всего, можно реализовать более простым способом, использовав лишь один инструмент Search API в Yandex Cloud (на момент написания статьи функционал был в Preview режиме)