Poison Message #1
У нас в RNDSOFT есть один проект, в котором очень интенсивно используется брокер сообщений RabbitMQ. Под "очень интенсивно" я подразумеваю, что это единственный канал взаимодействия десятков сервисов - никаких вам HTTP и REST. И в этой статье мы рассмотрим понятие "Poison Message" и как с ним можно жить.
Оказалось, что постановка проблемы тянет на отдельную статью, поэтому для нетерпеливых сразу даю ссылку на сам алгоритм.

Постановка проблемы
Когда в нашу систему залетают данные (сообщения), мы никогда не можем быть уверены, что же именно залетело, пока не выполним какие-нибудь действия наподобие валидации. Даже если мы всё покрыли тестами, контрактами и валидациями, всегда может появиться админ или дежурный, которые случайно отправит что-то не то или не туда.
Если мы говорим о брокере сообщений (и не важно, это Apache Kafka или RabbitMQ), то проблема заключается в том, что если сервис-получатель не может обработать сообщение (💀), то оно возвращается в начало очереди (или offset просто не перемещается вперед в терминологии Kafka). В этом случае сообщение будет получено нами снова и снова до тех пор, пока мы каким-то образом не обработаем его.
Вот некоторые причины по которым сервис-получатель может не суметь обработать сообщение:
- в теле сообщения находится какая-то дичь, вместо требуемого JSON или, на худой конец, XML;
- сервис завершился в момент обработки сообщения (например из-за бага или получил команду завершиться);
- сервис был убит (например к нам пришел OOM);
- в теле сообщения по виду всё хорошо (все поля на месте), но имеется какой-нибудь неверный идентификатор, в результате чего получаем ошибку;
- кто-то перезапустил или обновил сервис.
Теоретически можно обработать каждый тип сообщения, каждый вид ошибки, но в реальности это оказывается невозможно. Кроме того, мы сами можем допустить ошибку в сложном кейсе при валидации запроса и когда-нибудь эта ошибка выстрелит нам в ногу или голову.
Для более глубокого понимания проблемы рассмотрим 2 варианта - получение "правильного" сообщения, которое по какой-либо причине не может быть обработано именно в данный момент, и получение "битого" сообщения, которое не может быть обработано никогда.
Обработка правильного сообщения
Допустим у нас идет поток сообщений, все работает штатно, но в какой-то момент отказывает БД. Мы не можем ничего сохранить, прочитать и сервис вообще не может выполнять свои функции. В этом случае сервис может/будет стараться обработать данное сообщение снова и снова (например с помощью аварийного завершения и перезапуска). Далее предположим что через 5 минут БД будет восстановлена и, в очередной раз, получив сообщение, мы успешно его обработаем и "побежим" дальше. Очередь, накопившаяся за время отказа БД, будет разобрана - все будут счастливы. Вместо недоступности БД можно выбрать любой вариант - недоступность внешнего API, невозможность продолжить работу по причине переполнения диска и миллион других вариантов.
Более радикальным является случай, когда сообщение не может быть обработано в следствии нашей собственной ошибки. И тут, как ни странно, можно применить тот же самый подход - пусть сервис будет неработоспособным некоторое время, за которое мы исправим ошибку, передеплоим (у нас ведь CI/CD и 20-ти минутный цикл до прода, не правда ли?) и сообщение не будет потеряно. Этот вариант не всегда подходит, особенно в on-premise решениях, где от состояния "новая версия готова" до "запущено на площадке заказчика" проходит от шести часов… Есть у нас и такие проекты 💪.
Особенность этого кейса в том, что данное сообщение нельзя потерять ни при каких обстоятельствах, поскольку это, например, электронный документ от гражданина, имеющий юридическую значимость и административную ответственность за потерю.
Обработка "битого" сообщения
Допустим, у нас идет поток сообщений, все работает штатно, но в какой-то момент к нам пришло сообщение, которое не может быть обработано ни при каких условиях. В качестве примера опять обратимся к on-premise (ака self-hosted) решениям, и предположим, что кто-то послал сообщение в виде XML, но с Content-Type: JSON и наш парсер умирает еще до валидации, приводя к аварийному завершению сервиса ☠.
И так, сервис падает, сообщение возвращается в очередь, сервис перезапускается, читает сообщение и снова падает… А на улице глубокая ночь по МСК, а в далёком Хабаровске уже рабочий день и сотрудники МФЦ не могут обработать заявления граждан с Портала Госуслуг, и Пенсионный Фонд уже ставит всех на уши….. Как вспомню - так вздрогну….
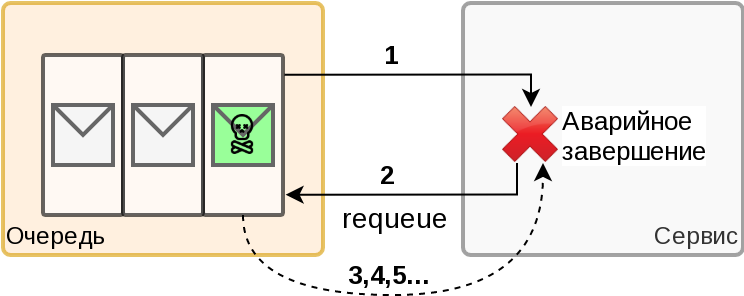
А надо всего-то удалить 1 (одно, Карл!) сообщение из очереди, ну или передвинуть offset в случае с Kafka. Именно такое сообщение называется "Poison Message" и оно выводит нашу систему (или часть системы) из строя на продолжительное время. Но работать ведь надо не считаясь с потерями всё равно! Особенно, если мы говорим о программном обеспечении "непрерывного цикла". Например Портал Госуслуг, с которым RNDSOFT имеет честь взаимодействовать, обрабатывает запросы граждан 24/7 без перерывов и выходных, во всех часовых поясах нашей необъятной страны.
Особенность этого кейса в том, что данное сообщение нужно потерять и забыть как в страшном сне (или на худой конец разобрать инцидент позднее).
Теперь я постараюсь более четко сформулировать проблему. Надежных способов отличить эти два кейса друг от друга не существует - мы никак не можем однозначно детектировать эти самые ядовитые сообщения. Поэтому нам нужен более-менее универсальный алгоритм, позволяющий справляться с данной коллизией с наименьшими потерями.
Проблема актуализирована и можно перейти непосредственно к решению: Вы хочете песен? Их есть у меня!