Вы хочете песен? Их есть у меня! (Poison Message #2)
Самое время рассмотреть “достаточно хороший” алгоритм для борьбы с Poison Message. Здесь будет уже специфика RabbitMQ и к Apache Kafka она не применима, точнее применима только частично - но это уже совсем другая история.
В первой части мы разобрали несколько примеров и сформулировали проблему Poison Message, здесь же рассмотрим сам алгоритм её решения.

Если коротко, то нам надо попытаться обработать “ядовитое” сообщение несколько раз и только после этого принять решение о его пропуске. Причем пропускать совсем нельзя, поэтому мы переложим такое сообщение в специальную очередь, из которой в дальнейшем сможем повторить в ручном режиме или просто дропнуть за ненадобностью.
Сам RabbitMQ не умеет отслеживать число передоставок, а только использует флаг redelivered. Таким образом, со стороны сервиса мы можем узнать только что это сообщение повторное, но вот повторяется оно второй раз или 5439й - никак. Кроме того RabbitMQ возвращает сообщение в голову очереди, тем самым блокируя получение следующих за ним сообщений и дальнейшую работу сервиса. Решением является ручная публикация сообщение в конец очереди и ручное же выставление собственного заголовка "x-delivery-count".
Алгоритм
Сценарий 1 - корректная работа
- Поставщик кладёт сообщение в очередь
- Сервис читает сообщение
- Сервис обрабатывает сообщение
- Сервис подтверждает обработку сообщения (ack)
- Брокер удаляет сообщение из очереди
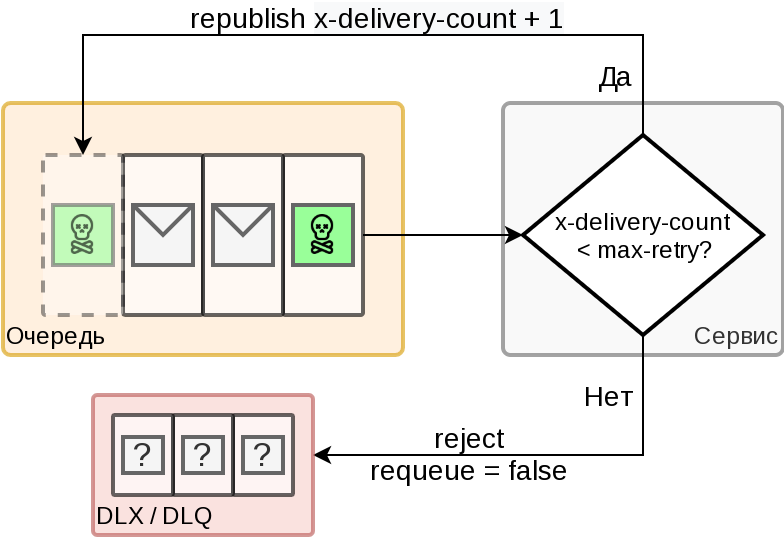
Сценарий 2 - Poison message
Когда мы точно знаем что есть проблема - и пытаемся её решить несколько раз
- Поставщик кладёт сообщение в очередь
- Сервис читает сообщение
- Сервис проверяет заголовок x-delivery-count (чтобы был не больше чем max retries)
- Сервису не удается обработать сообщение, но он не завершается
- Сервис создает копию сообщения и увеличивает значение x-delivery-count на 1
- Сервис публикует сообщение в конец очереди и подтверждает (ack) обработку исходного сообщения
- Брокер удаляет исходное сообщение из очереди
- Шаги 2-7 повторяются max retries раз
- Сервис читает сообщение
- Сервис отклоняет сообщение (reject, requeue = false)
- Брокер помечает сообщение флагом, x-death
- Брокер отправляет сообщение в dead-letter-exchange
Сценарий 3 - Аварийное завершение сервиса
- Поставщик кладёт сообщение в очередь
- Сервис читает сообщение
- Сервис аварийно завершается ☠
- Брокер обнаруживает разрыв и ставит сообщение на переотправку
Сервис перезапускается - Сервис читает сообщение
- Сервис обнаруживает заголовок redelivered=true
Сервис создает копию сообщения и увеличивает значение x-delivery-count на 1 - Сервис публикует сообщение в конец очереди и подтверждает (ack) обработку исходного сообщения
- Брокер удаляет исходное сообщение из очереди
- Далее события развиваются по Сценарию 1 или Сценарию 2
⚠ ВНИМАНИЕ ⚠
Если сервис обнаруживает redelivered=true, то он даже не пытается провести обработку сообщения, поскольку это вновь может привести к падению без возможности разорвать цикл перезапусков. Вместо этого сервис сразу публикует сообщение в конец очереди и запускает Сценарий 2.
Публиковать в отдельную очередь или использовать Dead Letter Exchange - это уже дело вкуса, но вот рассмотреть ограничения стоит внимательно:
- при таком подходе нарушается порядок следования сообщений. Если у вас есть жёсткие требования к очередности - надо искать иной выход;
- если очередь большая, то публикация в конец будет приводить к большой задержке обработки, а это не всегда приемлемо;
- если сообщение всего одно - то оно мгновенно исчерпает лимиты на обработку (max retries) и сразу уйдет в DLX.
Этот алгоритм, конечно, не является идеальным и единственно верным, однако он хорошо зарекомендовал себя как алгоритм общего назначения со строгими гарантиями отсутствия потерь при возникновении нештатных ситуаций. Для тех кому он не подходит, или кому просто интересно - я накидаю побольше ссылок с комментариями. Всем спасибо!
- FAQ: When and how to use the RabbitMQ Dead Letter Exchange - для RabbitMQ;
- Kafka Connect Deep Dive – Error Handling and Dead Letter Queues - много и подробно для Kafka;
- Poison Message Handling - нативная поддержка x-delivery-count в RabbitMQ;
Фундаментальные ресурсы по теме распределенных систем:
- Enterprise Integration Patterns - тут можно закопаться надолго, но это маст-хев для архитекторов и техлидов, проектирующих сложные системы;
- Designing Data-Intensive Applications - основа основ от Мартина Клепмана. Даёт полное понимание всех нюансов и граничных кейсов в сложных системах. Рекомендую перечитывать раз в год. Находил на русском языке.