Infra3: Мониторинг, Event Logging и сбор логов

Сегодня поговорим про то, что мы используем для мониторинга, логирования 👀событий, а также централизованного сбора логов инфраструктуры RNDSOFT. Эта статья продолжение небольшого цикла Infra про нашу инфраструктуру.
Infra1: Service Discovery, Cloud Native Proxy и деплой - первая статья цикла про различные современные штуки, которые мы используем для запуска и масштабирования приложений.
Infra2: Consul Registrator - вторая статья про замечательный инструмент.
Infra3: Мониторинг, Event Logging и сбор логов - третья статья про мониторинг.
Infra4: ...дальше видно будет...
Что мы используем?
Prometheus давно стал стандартом de facto, если у вас микросервисная архитектура. Мы его используем в гармоничном сочетании с consul service discovery, чтобы смотреть за нашими инстансами в облаках, виртуалках на bare metal, colocation и микросервисами, просто микросервисами. Далее добавим сюда ELK и сбор логов. Поскольку основной стэк, используемый у нас, строится на Ruby, то некоторые сервисы у нас скорее "макро", чем "микро", но на инфраструктуру это не влияет. Для мониторинга мы используем:
Теперь поговорим про каждый инструкмент в отдельности и об их взаимосвязях.
node-exporter
Инстансы виртуальных машин в облаках и на bare metal серверах мы мониторим с помощью node-exporter, который первым делом раскатывается на все новые машины при их создании. В docker-compose файле node-exporter мы указываем тэг monitoring в environment для того чтоб случилась магия service discovery:
Про то как как с помощью environment передавать настройки в консул более подробно в прошлой статье https://blog.rnds.pro/009-infra2
В данном случае node-exporter при указании этого параметра попадает в Consul, а из Consul через механизм SD сразу в Prometheus. Как говорится, что попадает в prometheus, остается в prometheus. Вот так выглядит в нашем Consul зарегистрированный node-exporter:
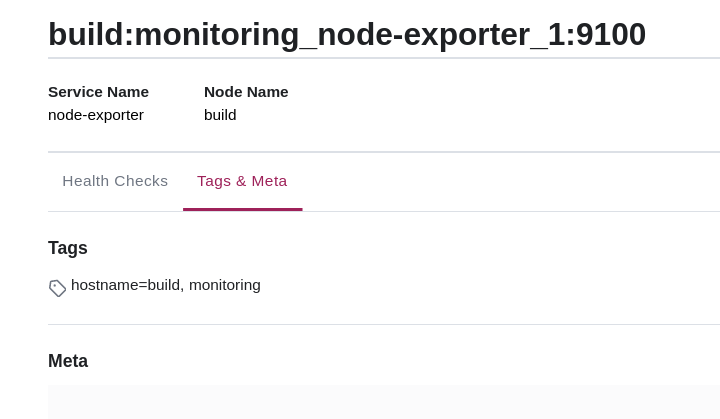
Сервисы в Consul у нас регистрируются с помощью consul-registrator. Он, как и node-exporter, безусловно ставится на каждую машину и автоматически регистрирует сервисы в Consul, если у них есть открытые порты о которых знает docker.
Для примера рассмотрим еще один exporter, который мы используем, ping-exporter. Он слушает порт 9427 и у него в environment также выставлен тег monitoring:
targets: - 1.1.1.1 ping: interval: 2s timeout: 3s history-size: 42 payload-size: 120
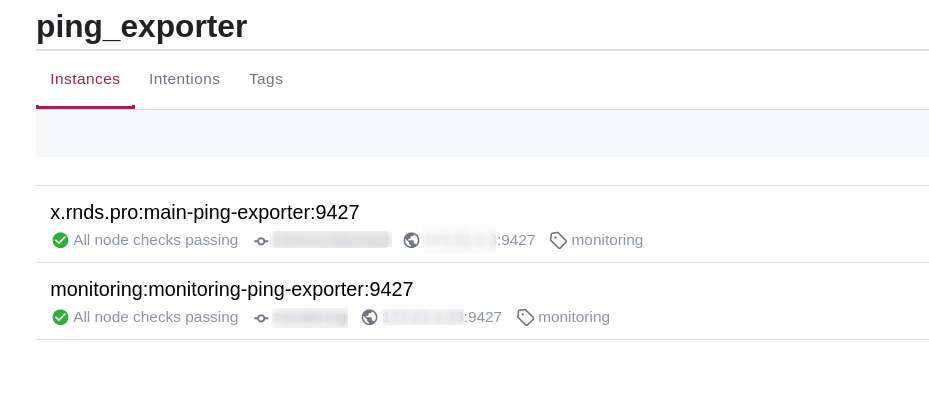
Prometheus
Аналогичным образом мониторятся и другие веб-приложения. Сам Prometheus узнает о том, что в Consul что-то появилось с помощью конфигурационной настройки consul_sd_config, которая позволяет Prometheus получать информацию по API из Consul Catalog.
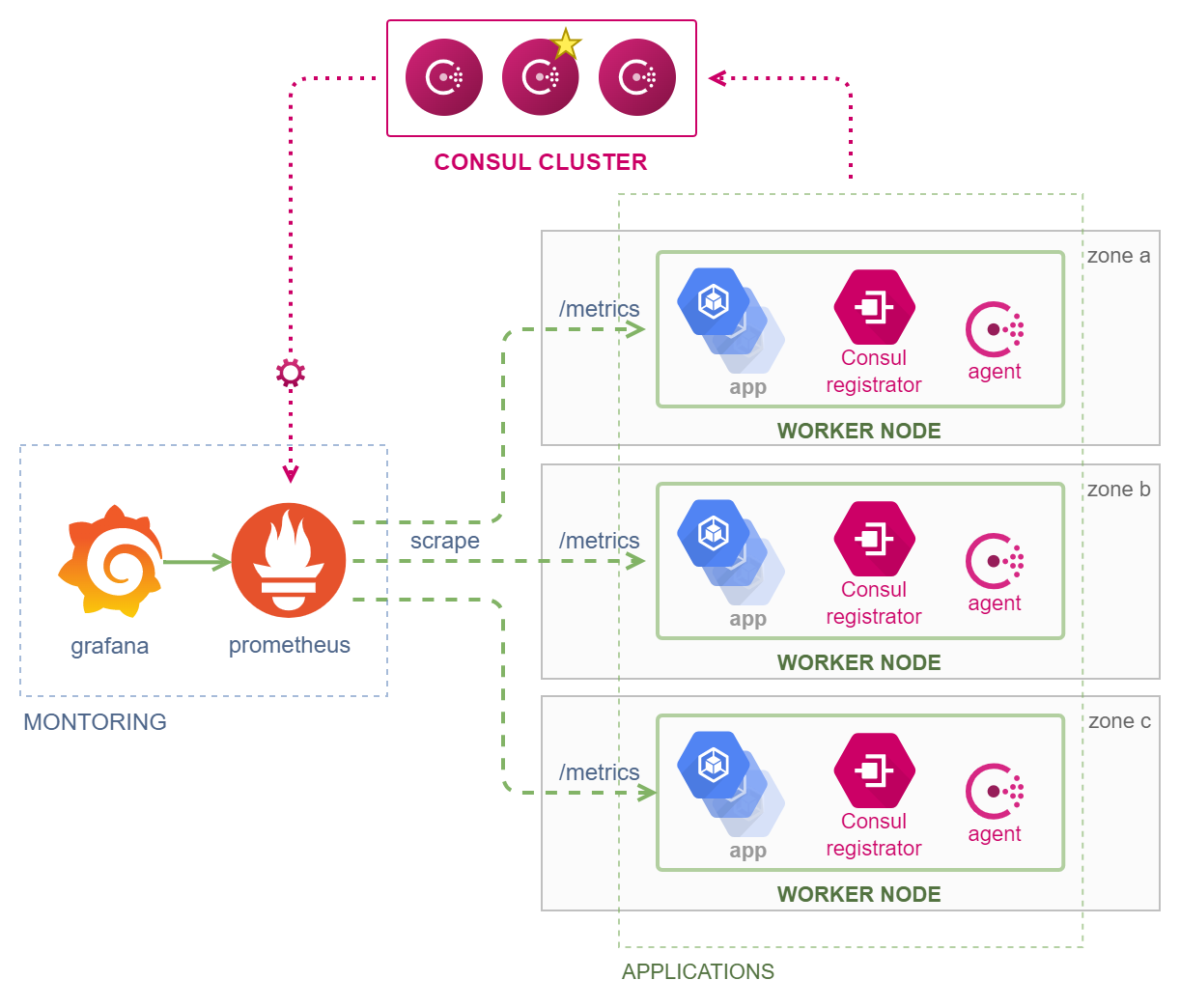
ELK
Тут дела обстоят немного иначе. Поскольку инфраструктурные моменты (диски, сеть память и пр.) у нас закрыты с помощью Prometheus, то на долю ELK остаются только бизнес метрики и Event Logging. Для Ruby on Rails приложений используем официальный гем elastic-apm. Поскольку это рельса, то никакой сложной настройки не требуется - всё что надо просто работает.
Vector
Следующая задача, которую нам надо решить в распределённой инфраструктуре - это сбор логов. Контейнеры, которые запускаются оркестратором, распределены по большому количеству узлов, и старый, добрый ручной docker logs уже не может нам помочь. Для сбора логов из докера и логов от системных процессов мы используем Vector (https://vector.dev). Он используется в централизованной топологии. В этом случае Vector-агенты, установленные на каждой машине, собирают и отправляют данные на Vector-агрегатор, где логи складываются. Более подробно о конфигурации Vector тут:
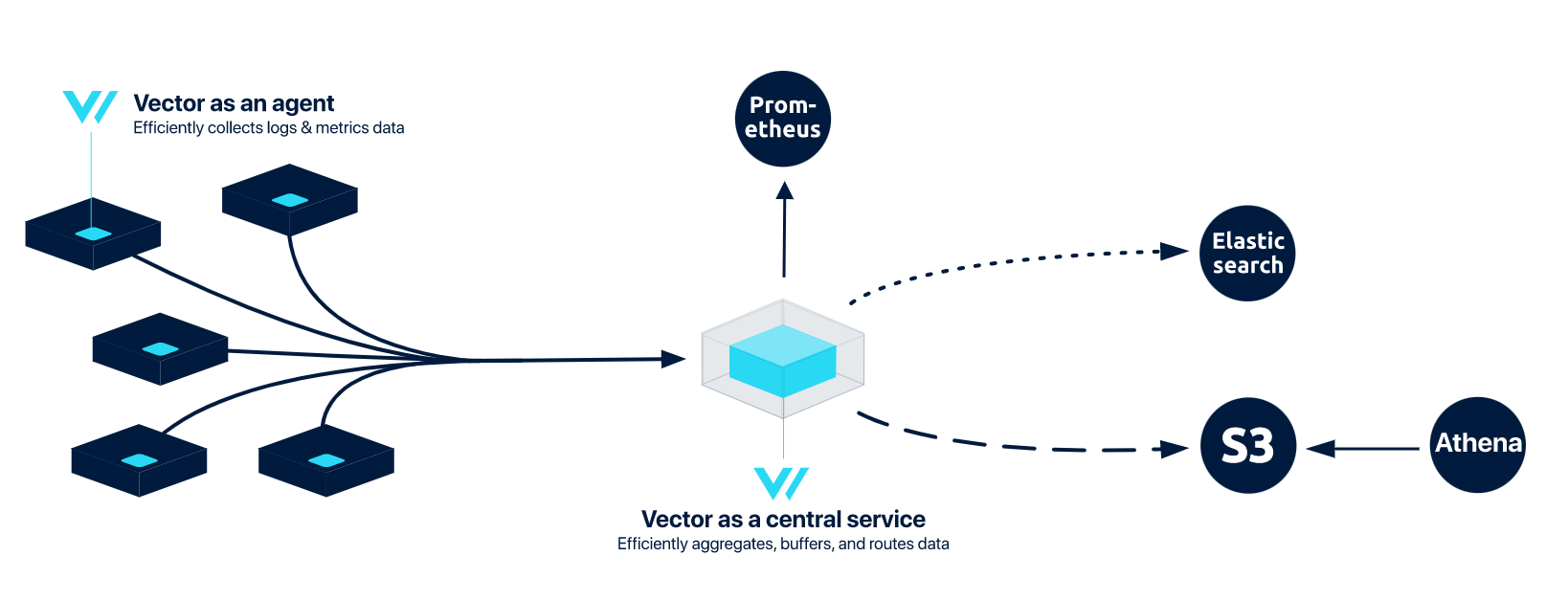
Конфигурация vector-agent
[sources.in] type = "docker_logs" [sinks.out] inputs = ["in"] type = "vector" address = "192.168.1.1:10000" buffer.type = "disk" buffer.when_full = "block" buffer.max_size = 1049000 # Если надо забирать логи из древного проекта с файловой системы [sources.rails] type = "file" include = ["/app/log/production.log"] or.log"] [sources.sidekiq] type = "file" include = ["/app/log/sidekiq.log"] [sinks.out] inputs = ["rails", "sidekiq"] type = "vector" address = "192.168.1.1:9098" buffer.type = "disk" buffer.when_full = "block" buffer.max_size = 1049000
Конфигурация vector-aggregator
В первом блоке описывается источник docker контейнеры для сбора логов из docker контейнеров, во втором блоке app-in описывается сбор логов из vector-агента, конфиг которого был показан выше. В блоке app-out описывается куда будет складывать файлы vector-агрегатор и какой будет у них шаблон названия файлов. В разделе out описана конфигурация, куда будут складываться файлы из докер контейнеров.
[sources.docker]
type = "vector"
address = "0.0.0.0:9099"
[sources.app-in]
type = "vector"
address = "0.0.0.0:9098"
[sources.app1-in]
type = "vector"
address = "0.0.0.0:10000"
[...]
[sinks.app-out]
encoding.codec = "ndjson"
inputs = ["app-in"]
type = "file"
path = "/etc/vector/logs/{{ host }}/{{ file }}-%Y-%m-%d.log"
[sinks.app1-out]
encoding.codec = "ndjson"
inputs = ["app1-in"]
type = "file"
path = "/etc/vector/logs/{{ host }}/{{ file }}-%Y-%m-%d.log"
[sinks.out]
encoding.codec = "ndjson"
inputs = ["docker", "local-docker"]
type = "file"
path = "/etc/vector/logs/{{ container_name }}-%Y-%m-%d.log"В данный момент эти логи складываются в файлы для ручного просмотра. Сейчас это proof of concept, в дальнейшем планируем собирать логи контейнеров в ElasticSearch или что-то подобное для более удобного просмотра и поиска.