There is no memory leak! Again!

Вернёмся к оптимизациям. И сегодня немного про память - про потребление, утечки и решение этих проблем. Раньше у нас уже была статья https://blog.rnds.pro/015-workerkiller и сейчас используемый инструмент получил очередное развитие.
На самом деле, инструмент получил развитие не "сейчас", а несколько месяцев назад, был успешно обкатан на проде, и с тех пор мы постепенно распространяем его на различные наши сервисы. Чтобы рассказать об улучшениях и результатах, надо сначала коротко напомнить о нашем основном тезисе прошлой статьи (или же перечитать её полностью):
Самым надёжным способом "отдать" память системе является завершение процесса. Тут следует оговориться — если у вас в приложении есть утечки памяти, то такой подход замаскирует проблему, не решив её окончательно, и проблема всё равно вас догонит и наподдаст вам в виде падения производительности, чрезмерной прожорливости приложения или редких плавающих багов. Так что если вы знаете, что у вас есть серьёзные утечки — займитесь профилированием, а не тушите огонь пирогами.
Вот теперь можно перейти к развитию и улучшениям :)
Первое улучшение - динамические ограничения на память.
Итак, раньше мы выделяли некоторый лимит для потребления памяти внутри приложения (так называемая RSS память) и при превышении этого порога запускали процедуру мягкой перезагрузки. На тот момент мы поддерживали мягкую перезагрузку для следующих подсистем:
- Phusion Passenger (через встроенную возможность
passenger-config detach-process); - Delayed Job (через плагин и штатный перезапуск воркера) ;
config.middleware.tap do |middleware|
killer = PassengerKiller.new
# Max requests per worker
middleware.insert_before(
Rack::Sendfile,
Middleware, limiter_klass: RequestLimiter, killer: killer,
min: 3000, max: 4000)
# Max memory size (RSS) per worker
middleware.insert_before(
Rack::Sendfile,
Middleware, limiter_klass: MemoryLimiter, killer: killer,
min: 300 * (1024**2), max: 400 * (1024**2))
endВсё работало прекрасно до некоторых пор, пока общая нагрузка на систему не выросла (в несколько раз), и нам не пришлось поднимать статические лимиты. Тут и пришло понимание, что статические лимиты - это очень не гибкая вещь. Решение оказалось вполне очевидное - рассчитывать допустимую границу в процентах "на лету". Алгоритм прост:
- Запускаемся и работаем несколько циклов/запросов. По умолчанию выбрали 16;
- Замеряем текущее потребление памяти (RSS) и высчитываем указанный процент, например 50%;
- Каждые N циклов/запросов проверяем собственное потребление, и если оно превысило рассчитанный порог - мягонько завершаемся;
Эти ограничения и мягкое завершение позволяют приложению потреблять столько памяти, сколько ему нужно - иногда бывают большие всплески, при которых потребление памяти вырастает более чем в 2 раза, но после этого такой толстенький воркер выводится из балансировки (спасибо Passenger) и завершается. Теперь конфигурация выглядит так:
# Max memory size (RSS) per worker is 150% of the # initial value (on 16 request) config.middleware.insert_before( Rack::Sendfile, Middleware, limiter_klass: MemoryLimiter, killer: killer, min: 0, max: 0.5)
Для примера возьмём наш боевой Object Store сервис для сохранения данных в различные S3 совместимые хранилища под кодовым названием "filator". Он запущен с использованием сервера приложений Phusion Passenger. Нагрузка на него составляет от 30 до 60 запросов в секунду, в зависимости от фазы луны.
- Число запущенных контейнеров: 2;
- Число воркеров внутри Passenger: 5;
- Потребление памяти после прогрева: 120МБ;
- Порог по памяти (+50%): 180МБ;
- Порог запросам: 3000-4000 штук;
В результате таких настроек мы имеем не более 2х перезапусков воркеров в минуту. Может ли это влиять на производительность? Ничуть!
Passenger очень качественно обрабатывает перезапуск (detach process) — сначала он запускает новый процесс-обработчик, потом останавливает выделение запросов старому, дожидается обработки всей его очереди и только потом завершает процесс.
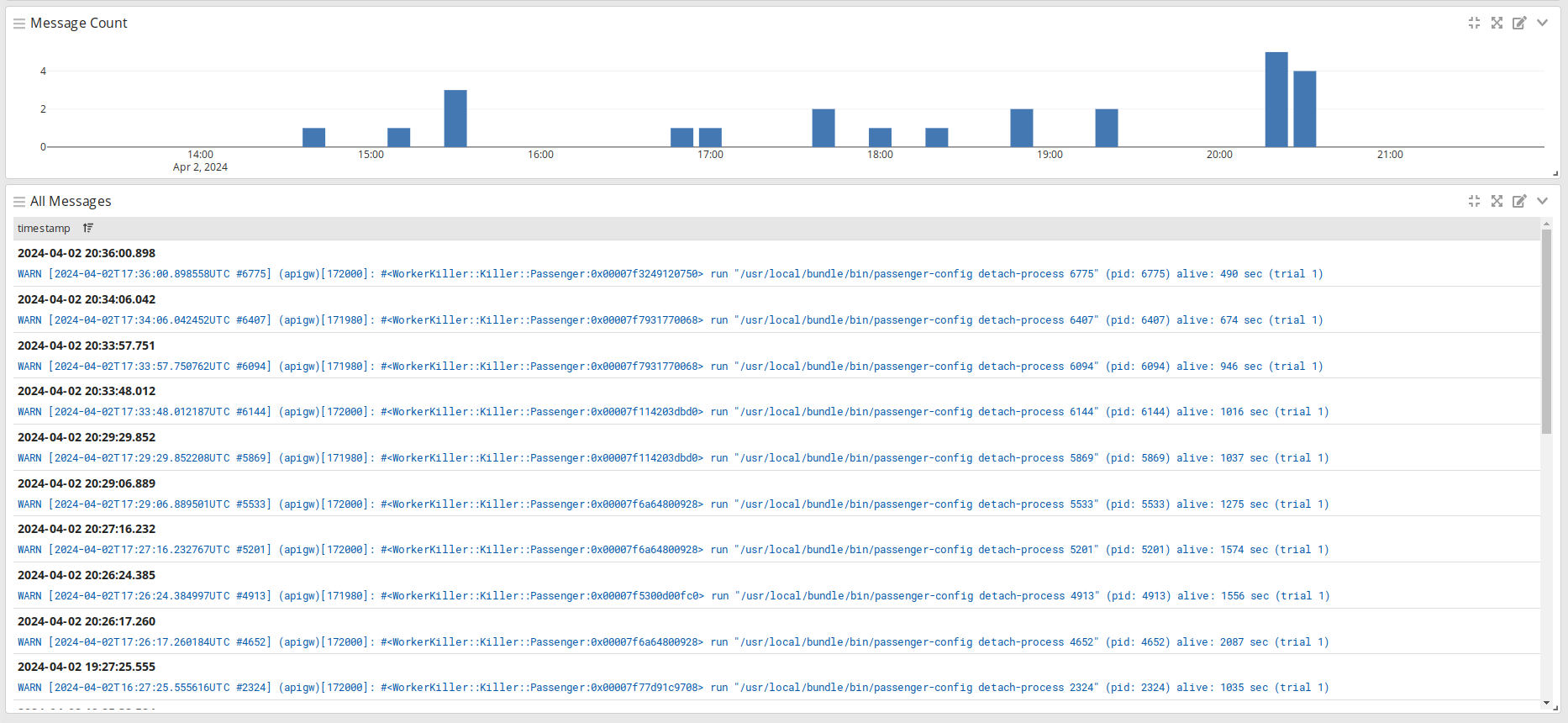
Ну и каков же результат? Вот момент выкатки на прод такой конфигурации:
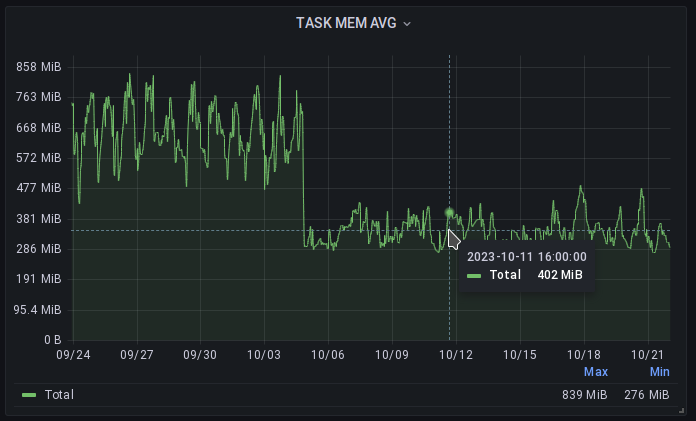
Если посмотреть на весь интервал (7 месяцев с момента запуска), то можно будет увидеть, что с ростом нагрузки (примерно в 2 раза) среднее потребление памяти на контейнер немного подросло и процентное ограничение показывает себя прекрасно:
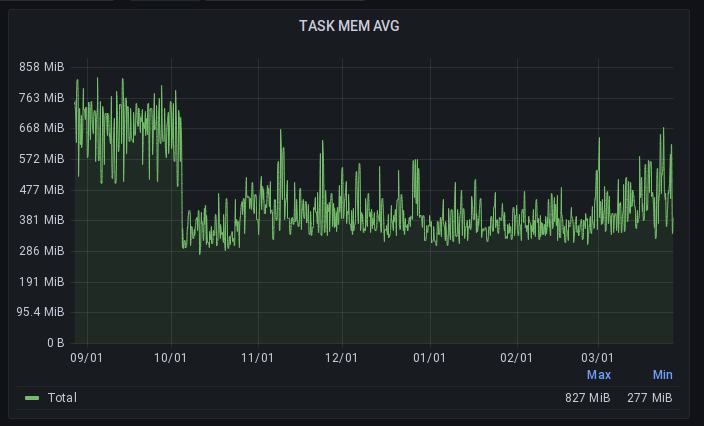
Аналогичная ситуация для совершенно другого сервиса, который использует Delayed Job для обработки фоновых запросов. Хорошо видно что, в течение нескольких месяцев происходит плавный рост потребления памяти (и установленных нами лимитов) и резкое сокращение, когда в сервисе включили динамический лимит в 130%:
Второе улучшение - поддержка Puma
Phusion Passenger, конечно, хорош, но периодически нам требуется чуть больше контроля над сокетом входящего запроса (об этом надеюсь подробно рассказать отдельно). В общем, мы наконец сделали очень качественный Killer для Puma! В этой части я расскажу о проблемах, с которыми нам пришлось столкнуться, и их решениях.
Проблемы
- Puma имеет несколько режимов работы в разных, так сказать, "осях":
Cluster / Single; - Phased Restart / Hot Restart;
- С прогрузкой (preload) кода приложения / без прогрузки;
- Особый экспериментальный (я бы сказал психоделический) режим
Fork-Worker;
Все эти режимы в разных вариантах могут сочетаться или не сочетаться между собой. Например, Fork-Worker всегда имеет один (рабочий!) экземпляр воркера, от которого форкает следующие по мере необходимости. Это приводит к накоплению утечек в самом этом воркере. Также в различных режимах Puma по-разному реагирует на системные сигналы HUP, USR1, USR2 и пр.
Но основная проблема заключается в том, что находясь "внутри" воркера, невозможно мягко и без потерь выполнить собственный перезапуск, поскольку мастер-процесс ничего не знает о ваших желаниях. В Passenger эта проблема решается утилитой passenger-config detach-process PID, которая как раз и сообщает мастер-процессу о необходимости снять нагрузку с определённого воркера, запустить новый и дождаться корректного завершения.
Решение
Для решения этой проблемы пришлось разобраться в системе плагинов для Puma и написать собственный, реализующий простой и надёжный механизм IPC для уведомления мастер-процесса о необходимости перезапуска воркера.
Суть плагина простая - в мастер-процессе запускаем слушатель unix-сокета, а из воркеров можем послать свой собственный номер. Получив номер, слушатель запускает процедуру мягкого рестарта. Код его очень простой - можно целиком разместить тут, чтоб дотошные читатели могли задать вопросы:
module WorkerKiller
class PumaPlugin
include Singleton
attr_accessor :ipc_path, :killer, :thread
def initialize
@ipc_path = File.join('tmp', "puma_worker_killer_#{Process.pid}.socket")
@killer = ::WorkerKiller::Killer::Puma.new(worker_num: nil, ipc_path: ipc_path)
log "Initializing IPC: #{@ipc_path}"
end
def config(puma)
puma.on_worker_boot do |num|
log "Set worker_num: #{num}"
@killer.worker_num = num
end
end
def start(launcher)
@runner = launcher.instance_variable_get('@runner')
launcher.events.on_booted do
@thread ||= start_ipc_listener
end
end
def start_ipc_listener
log 'Start IPC listener'
Thread.new do
Socket.unix_server_loop(ipc_path) do |sock, *args|
if (line = sock.gets)
worker_num = Integer(line.strip)
if (worker = find_worker(worker_num))
log "Killing worker #{worker_num}"
worker.term!
end
end
rescue StandardError => e
log("Exception: #{e.inspect}")
ensure
sock.close
end
end
end
def find_worker(worker_num)
worker = @runner.worker_at(worker_num)
unless worker
log "Unknown worker index: #{worker_num.inspect}. Skipping."
return nil
end
unless worker.booted?
log "Worker #{worker_num.inspect} is not booted yet. Skipping."
return nil
end
if worker.term?
log "Worker #{worker_num.inspect} already terminating. Skipping."
return nil
end
worker
end
def log(msg)
warn("#{self.class}[#{Process.pid}]: #{msg}")
end
end
endПрофит!
Само собой нужны пруфы полученного профита при переходе на Puma, и их есть у меня:
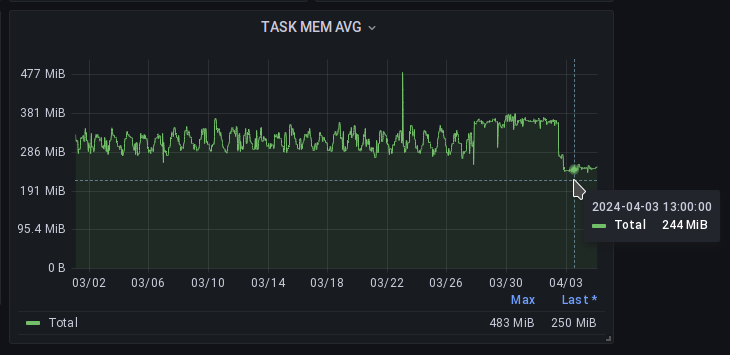
С 28-го по 4-е смотреть не стоит - там происходил замер и тюнинг 😁
А вот так выглядит от самого первого момента, когда перешли на динамические лимиты памяти:
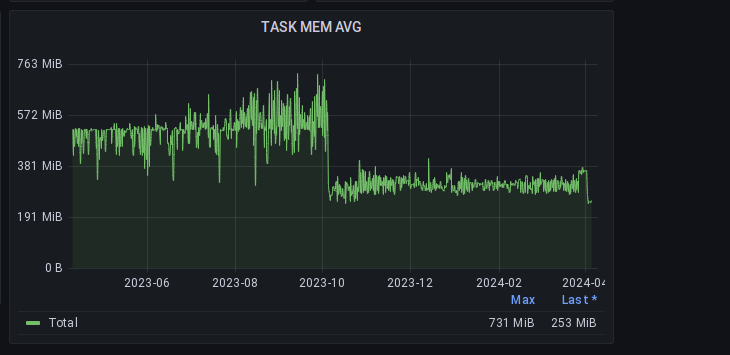
Заключение
Как обычно, мы делимся нашим опытом, который уже обкатан на проде и дал свои результаты. Наш гем ❤️💎 WorkerKiller 💎❤️ не исключение - используйте на здоровье!
PS
Очень ждём, когда наши коллеги из соседних отделов запилят в него интеграцию с Sidekiq :)