Генри Форд, диалектический материализм и при чем здесь автоматическая подготовка машин в облаке
Любовь это… Когда она смотрит со слезами на глазах на твой огромный… Автоматически масштабируемый кластер в облаке
Лучшая машина - новая машина!

В этой статье мы расскажем, как научились делать автоматическую подготовку виртуальных машин в облаке. Мы - простые разработчики и DevOps инженеры, уже не представляем свою жизнь без конвейерной и контейнерной доставки приложений, но теперь пришло время пойти дальше и внедрить конвейер и в инфраструктуре. Аналогично тому, как Генри Форд стал впервые использовать конвейер для поточного производства автомобилей (первый конвейер был запущен в 1913 г. для сборки генераторов), точно также DevOps инженеры спустя ровно 100 лет (первый выпуск docker 13 марта 2013г.) стали использовать аналогичную технологию конвейерной сборки и поточной доставки приложений в продуктовое (и не только) окружение.
Генри Форд начал массово производить авто ("Автомобиль для всех"), что стало апогеем индустриальной эпохи, а спустя 100 лет массово начали производить ПО ("ПО в каждый карман" прим. автора), что стало апогеем постиндустриальной эпохи, что плавно приводит нас к принципу развития в диалектическом материализме… Но, пожалуй, давайте перейдем к технической части.
Мы уже рассказывали в прошлых статьях о нашей облачной инфраструктуре. Раз , два , три и даже четыре. Пришло время двигаться дальше. В нашем облаке уже достаточно много машин (чуть больше 20). И мы, когда разворачивали их, делали все это через ansible и статический inventory файл, добавляли туда адреса, добавляли машину в нужные группы, чтобы на машине разворачивались нужные контейнеры из разных групп, мониторинг, логирование и т.д. И нам это уже изрядно надоело. Задача: при масштабировании группы виртуальных машин в облаке при старте машины, не править inventory файл, не запускать на машине руками нужные плейбуки, а как-то это все автоматизировать.
1. Подготовка
- Группу виртуальных машин в Yandex Cloud.
- Консольную утилиту yc для работы с API Yandex Cloud.
- Workflow Engine n8n или любой другой программируемый обработчик webhook’ов.
- cloud-init - инструмент для настройки облачных серверов.
- ansible + динамический inventory в виде скрипта на python.
Из всех ингредиентов самый неизвестный это, пожалуй, n8n, стоит сказать пару слов об этом инструменте. Если вкратце, n8n - это флэт-уайт в мире workflow engines. Мы смотрели на другие аналоги: huginn, temporal, dagster, windmill, apache airflow. Из всех вышеперечисленных workflow engines n8n оказался самым симпатичным визуально, а также при беглом первом взгляде достаточным, чтобы удовлетворить наши потребности.
2. Deploy и автоматическая подготовка
Итак, наша схема работы и провижининга машин выглядит следующим образом:
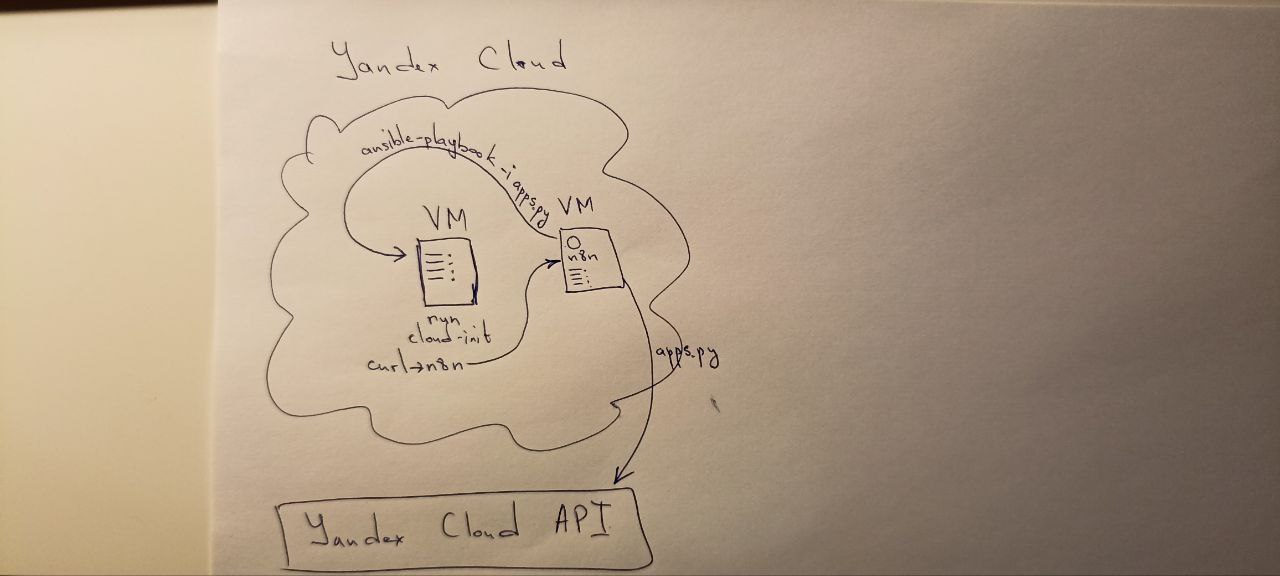
При запуске новой машины она (через cloud-init) шлёт POST-запрос со своими данными в Webhook Engine (n8n), а там с помощью динамического инвентаря на этой новой машине катается всё необходимое для включения машины в кластер.
ansible
Cкрипт на python, который будет формировать наш динамический inventory:
#!/usr/bin/env python3
import json, os, sys, subprocess, argparse, yaml
from collections import namedtuple
# хз какая там будет версия питона, но я бы заменил на dataclasses
MachineName = namedtuple("MachineName", ['name', 'zone_id'])
class MachineInfo:
NOMAD_META_PREFIX = 'nomad_'
def __init__(self, raw_data):
self._raw_data = raw_data
@property
def name(self):
return self._raw_data['name']
@property
def ip(self):
return self._raw_data['network_interfaces'][0]['primary_v4_address']['address']
@property
def metadata(self):
return self._raw_data.get('metadata', {})
@property
def roles(self):
roles = self.metadata.get('roles', '').split(',') + self.metadata.get('role', '').split(',')
return list(set(filter(None, roles)))
@property
def nomad_metadata(self):
return {k:v for k,v in self.metadata.items() if k.startswith(self.NOMAD_META_PREFIX)}
@property
def zone_group(self):
return f"zone_{self._raw_data['zone_id'][-1]}"
@property
def user(self):
ud = yaml.safe_load(self.metadata['user-data'])
return ud['users'][0]['name']
class YClient:
def list_machines(self):
result = self._execute_cmd("compute", "instance", "list")
return list(MachineName(name=it['name'], zone_id=it['zone_id']) for it in result)
def get_machine_info(self, machine_name: str):
result = self._execute_cmd("compute", "instance", "get", "--full", machine_name)
return MachineInfo(result)
def _execute_cmd(self, *command):
if not command:
raise ValueError("Empty command")
if command[0] != "yc":
command = ["yc", *command]
if "--format" not in command:
command.extend(["--format", "json"])
output = subprocess.check_output(command)
return json.loads(output)
def build_ansible_definition(client, host_filter):
result = {
"_meta": {
"hostvars": {}
}
}
hostvars = result['_meta']['hostvars']
for it in client.list_machines():
if host_filter and it.name != host_filter:
continue
machine_info = client.get_machine_info(it.name)
vars = hostvars[machine_info.name] = machine_info.nomad_metadata
vars['ansible_host'] = machine_info.ip
vars['ansible_ssh_host'] = machine_info.ip
vars['ip'] = machine_info.ip
vars['ansible_ssh_user'] = machine_info.user
for role in machine_info.roles:
role_data = result[role] = result.get(role, {})
role_data['hosts'] = role_data.get('hosts', []) + [machine_info.name]
role_data['vars'] = {"role": role}
zone = machine_info.zone_group
zone_data = result[zone] = result.get(zone, {})
zone_data['hosts'] = zone_data.get('hosts', []) + [machine_info.name]
zone_data['vars'] = {"zone": zone}
all_data = result['all'] = result.get('all', {})
all_data['hosts'] = all_data.get('hosts', []) + [machine_info.name]
all_data['vars'] = {}
return result
parser = argparse.ArgumentParser()
parser.add_argument(
"--host",
help="Display vars related to the host"
)
parser.add_argument(
"--list",
action="store_true",
help="Show JSON of all managed hosts"
)
if __name__ == '__main__':
args = parser.parse_args()
client = YClient()
if args.host:
definition = build_ansible_definition(client, args.host)
else:
definition = build_ansible_definition(client, os.environ.get('INSTANCE_NAME', None))
json.dump(definition, sys.stdout, indent=2, ensure_ascii=False)
Скрипт собирает нам JSON из данных, которые получает по API через утилиту yandex cli, если хотите узнать, какой формат должен быть у inventory в формате JSON, то из статического inventory можно сделать экспорт в json следующей командой
ansible-inventory -i inventory/hosts.ini –list > ./inventory.json
packer
C помощью packer создали образ виртуальной машины, конфиг (не полностью) образа packer далее
.......
source "yandex" "autogenerated_1" {
disk_type = "network-hdd"
folder_id = "${var.folder_id}"
image_description = "debian 12 image with docker and ansible and run CLOUD-INIT through n8n"
image_family = "debian"
image_name = "debian-12-base-cloud-init-n8n-${local.timestamp_image}"
disk_size_gb = 50
source_image_family = "debian-12"
ssh_username = "debian"
subnet_id = "std4dhhhrtef3"
token = "${var.token}"
use_ipv4_nat = true
zone = "ru-central1-a"
}
build {
sources = ["source.yandex.autogenerated_1"]
provisioner "file" {
source = "10_autoprepare_instance.cfg"
destination = "/tmp/10_autoprepare_instance.cfg"
}
provisioner "file" {
source = "hostname.json"
destination = "/tmp/provision_params.json"
}
provisioner "shell" {
inline = ["sudo apt-get update -y", "sudo apt-get install -y ansible python3 python3-pip apt-transport-https ca-certificates curl gnupg-agent software-properties-common mtr-tiny traceroute mc vim git rsync nload strace tmux dnsutils tcpdump htop jq gettext-base",
"sudo mv /tmp/10_autoprepare_instance.cfg /etc/cloud/cloud.cfg.d/10_autoprepare_instance.cfg",
"sudo mv /tmp/provision_params.json /opt/provision_params.json",
.......Тут самое главное это provision_params.json , содержащий все необходимые данные для провижининга (оказалось, что достаточно только hostname):
{"HOSTNAME”:”META_HOSTNAME"}и 10_autoprepare_instance.cfg - cloud-init конфиг.
cloud-init
Конфиг/скрипт 10_autoprepare_instance.cfg будет запускаться на виртуальной машине при ее первом старте:
#cloud-config
---
package_update: true
package_upgrade: true
users:
- name: cloudname
shell: /bin/bash
ssh_authorized_keys:
- ssh-rsa esntastoDasentarstANzaC1yc2EAAAABA
sudo: ALL=(ALL) NOPASSWD:ALL
runcmd:
- sudo cp /opt/provision_params.json /home/cloudname/provision_params.json
- export META_HOSTNAME=$(curl -H Metadata-Flavor:Google 169.254.169.254/computeMetadata/v1/instance/?recursive=true | jq .name | tr -d '"')
- 'sudo sed -i "s/META_HOSTNAME/$META_HOSTNAME/g" /home/cloudname/provision_params.json'
- 'sleep 1'
- 'curl -s -X POST -H "Content-type: application/json" -d @/home/cloudname/provision_params.json http://URL_N8N_INSTNACE/webhook/87d66f08-ca37-4404-85b4-d9defc114'
Тут мы просто создаем файл (упс, что-то не получилось сразу сделать JSON в строке с curl, чтобы cloud-init был доволен при старте инстанса, поэтому через файл) provision_params.json с hostname нашего инстанса и передаем его в POST запросе, который отправляется в n8n, далее n8n запускает ansible-playbook c нашим динамическим inventory и делает provisioning инстанса в облаке, после окончания наш инстанс находится в кластере consul, nomad и готов принимать полезную нагрузку.
n8n
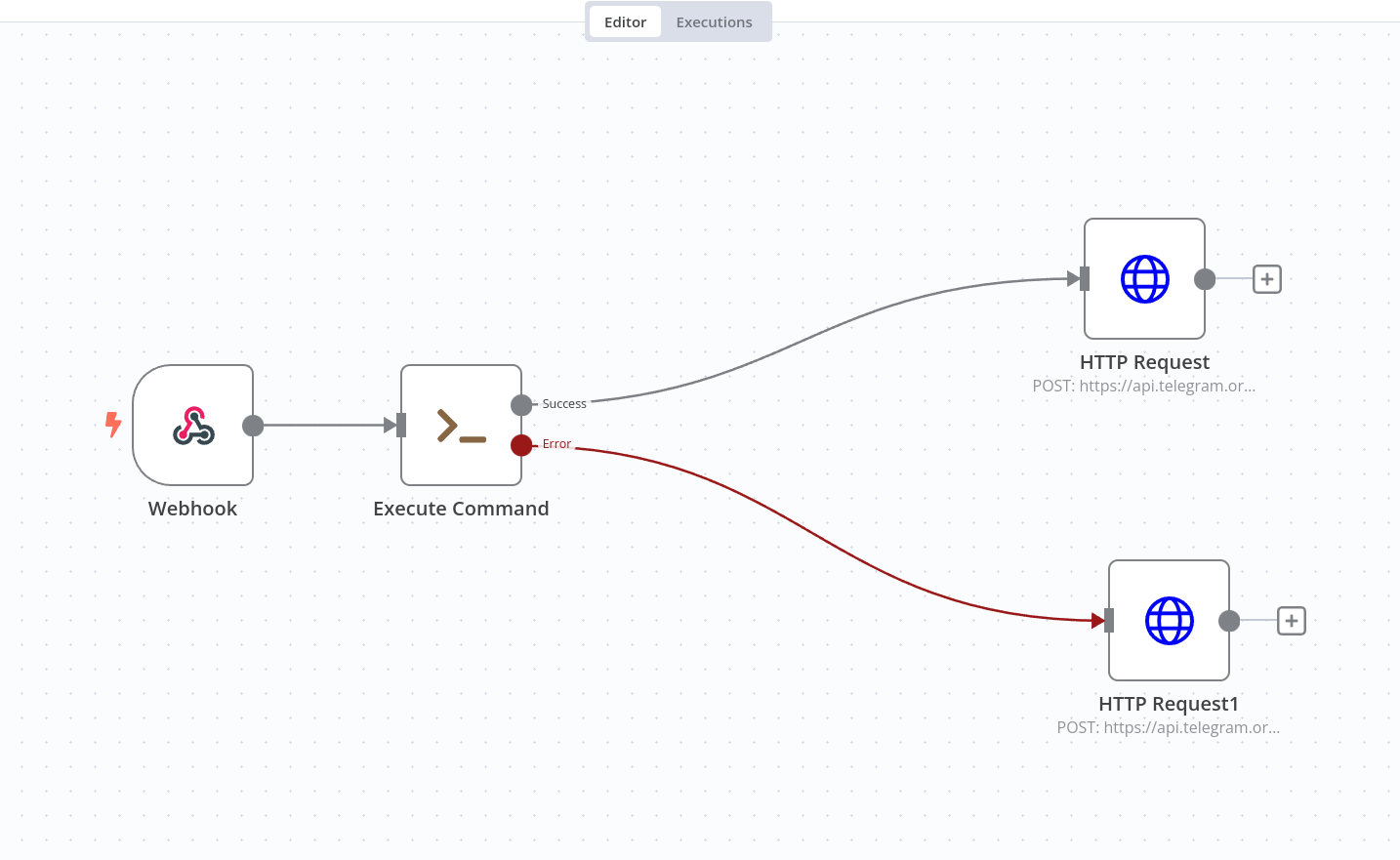
Задеплоили n8n на машине внутри нашего облака. И в стиле nocode (ну почти) в его интерфейсе сделали следующий workflow:
- точка входа - это webhook;
- в шаге Execute Command мы запускаем
ansible-playbook -i apps.py playbooks/do_everything_in_the_best_way.yml; - после успешного provisioning отправляем уведомление в Telegram о том, что инстанс подготовлен и готов к работе.
3. Итоги
В результате теперь нам достаточно просто исправить одну цифру: кол-во инстансов в интерфейсе Яндекс облака (да-да, мы знаем про существование terraform, но не все же сразу), которое требуется нам для работы, а всё остальное произойдет автоматически. Теперь мы можем получить в облаке много новых машин за очень короткое время. Можно пойти еще дальше и воспользоваться автоматическим масштабированием, но мой техлид больше всего боится "когда на автоматическом сливном бачке нет ручной кнопки «слив»", так что этот вопрос придется немного отложить.